Overview
Imitation Learning is a promising approach to endow robots with various complex manipulation capabilities. By allowing robots to learn from datasets collected by humans, robots can learn to perform the same skills that were demonstrated by the human. Typically, these datasets are collected by having humans control robot arms, guiding them through different tasks. While this paradigm has proved effective, a lack of open-source human datasets and reproducible learning methods make assessing the state of the field difficult. In this paper, we conduct an extensive study of six offline learning algorithms for robot manipulation on five simulated and three real-world multi-stage manipulation tasks of varying complexity, and with datasets of varying quality. Our study analyzes the most critical challenges when learning from offline human data for manipulation.
Based on the study, we derive several lessons to understand the challenges in learning from human demonstrations, including the sensitivity to different algorithmic design choices, the dependence on the quality of the demonstrations, and the variability based on the stopping criteria due to the different objectives in training and evaluation. We also highlight opportunities for learning from human datasets, such as the ability to learn proficient policies on challenging, multi-stage tasks beyond the scope of current reinforcement learning methods, and the ability to easily scale to natural, real-world manipulation scenarios where only raw sensory signals are available.
We have open-sourced our datasets and all algorithm implementations to facilitate future research and fair comparisons in learning from human demonstration data. Please see the robomimic website for more information.
Why is learning from human-labeled datasets difficult?
We explore five challenges in learning from human-labeled datasets.
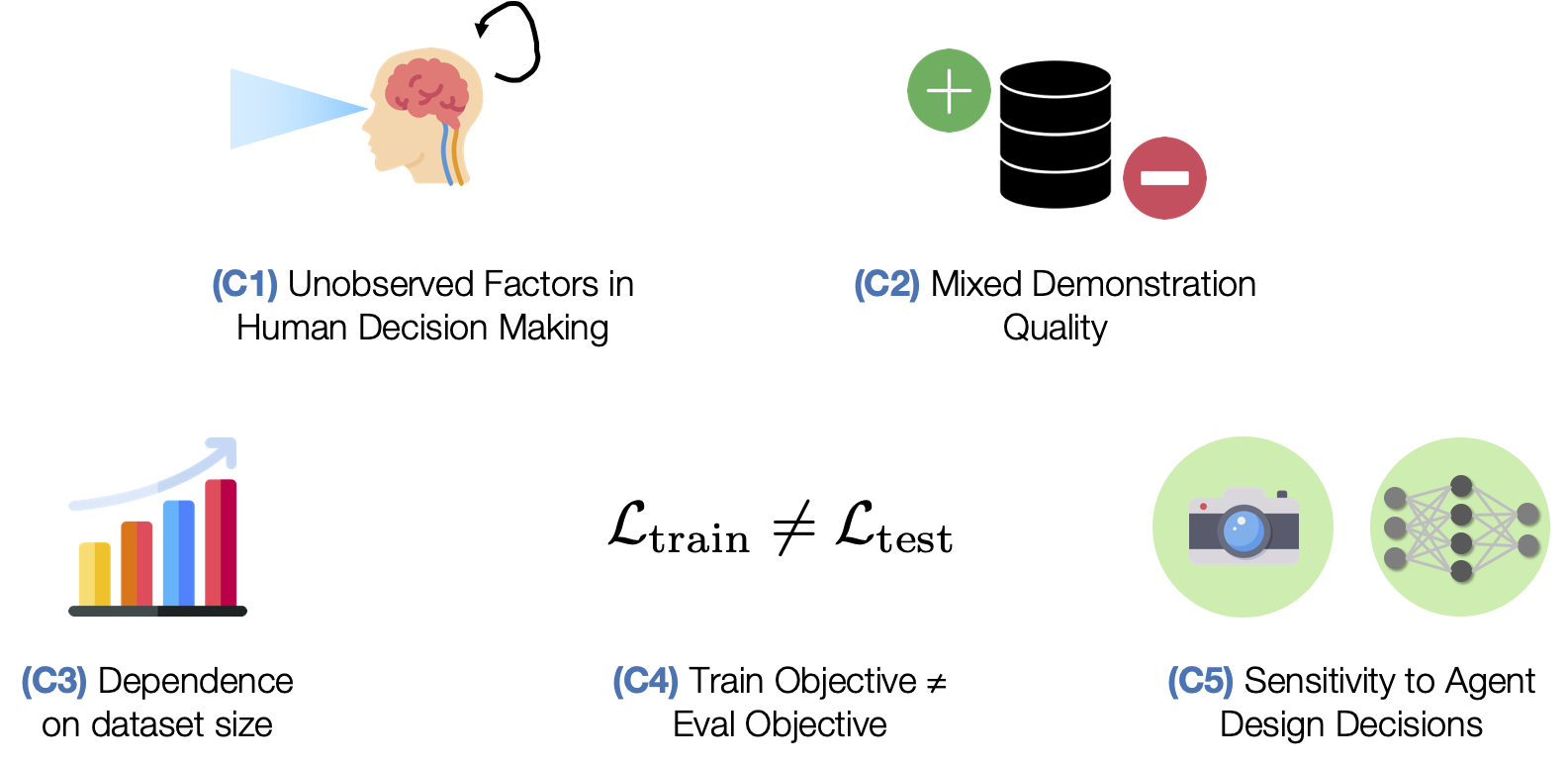
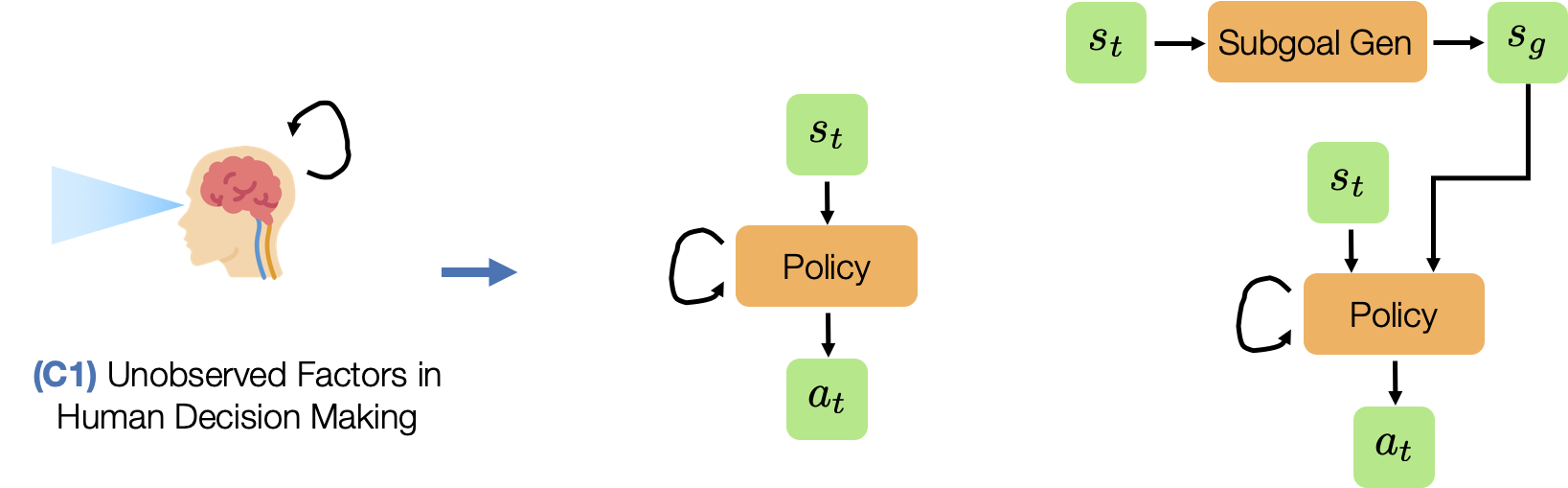
- (C1) Unobserved Factors in Human Decision Making. Humans are not perfect Markovian agents. In addition to what they currently see, their actions may be influenced by other external factors - such as the device they are using to control the robot and the history of the actions that they have provided.
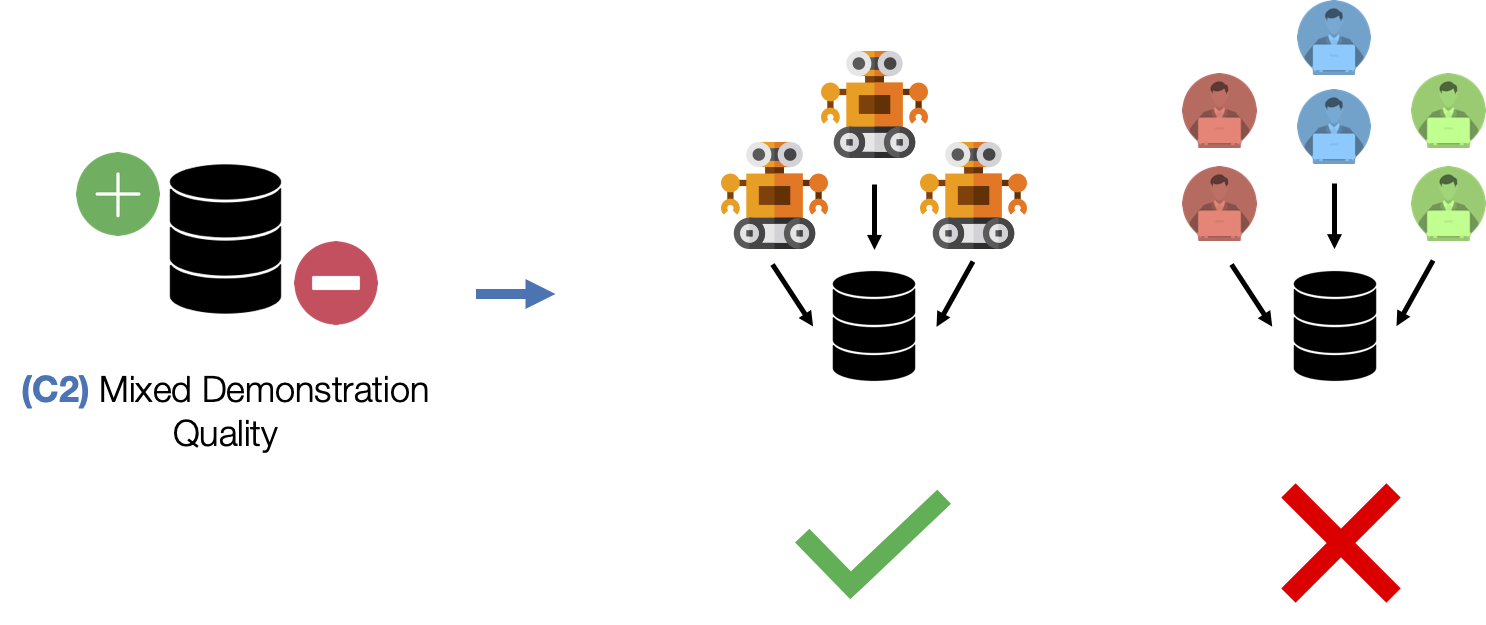
- (C2) Mixed Demonstration Quality. Collecting data from multiple humans can result in mixed quality data, since some people might be better quality supervisors than others.
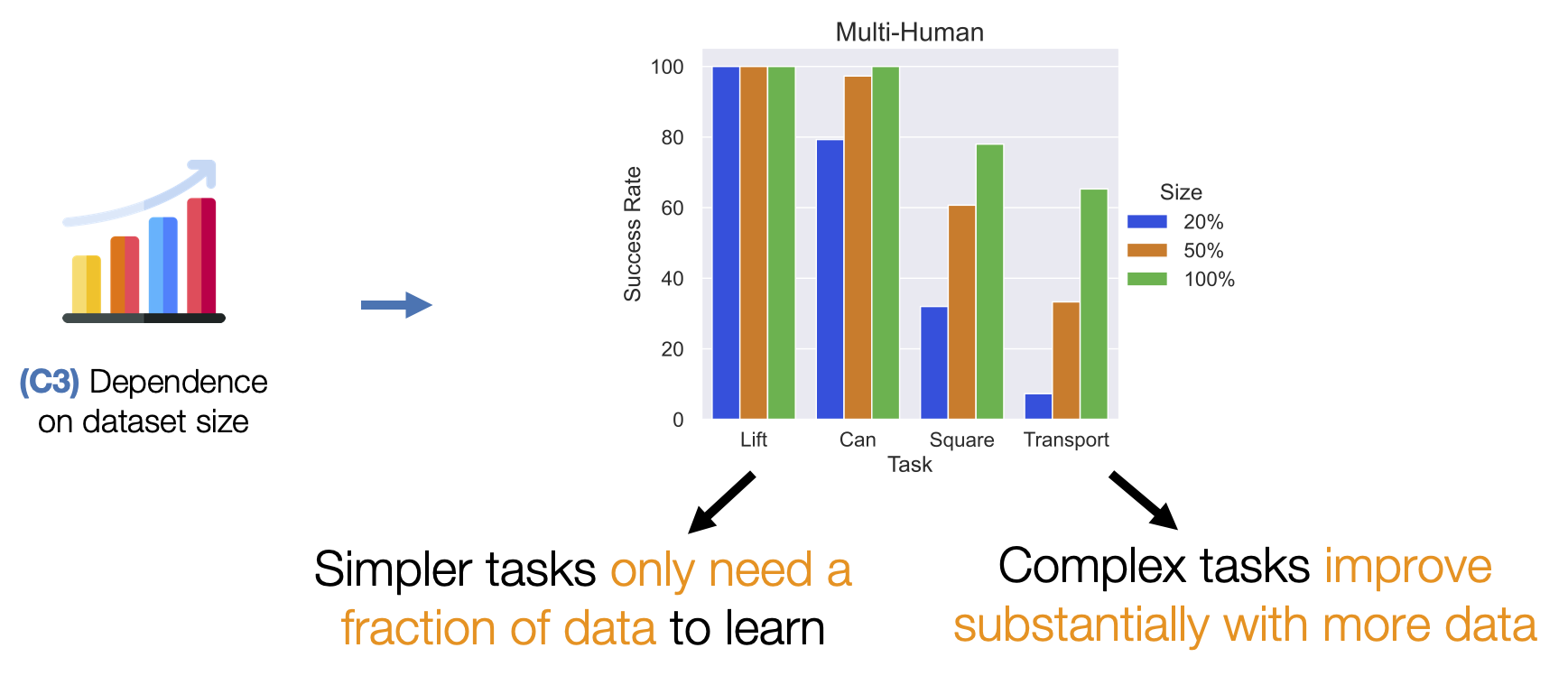
- (C3) Dependence on dataset size. When a robot learns from an offline dataset, it needs to understand how it should act (action) in every scenario that it might encounter (state). This is why the coverage of states and actions in the dataset matters. Larger datasets are likely to contain more situations, and are therefore likely to train better robots.
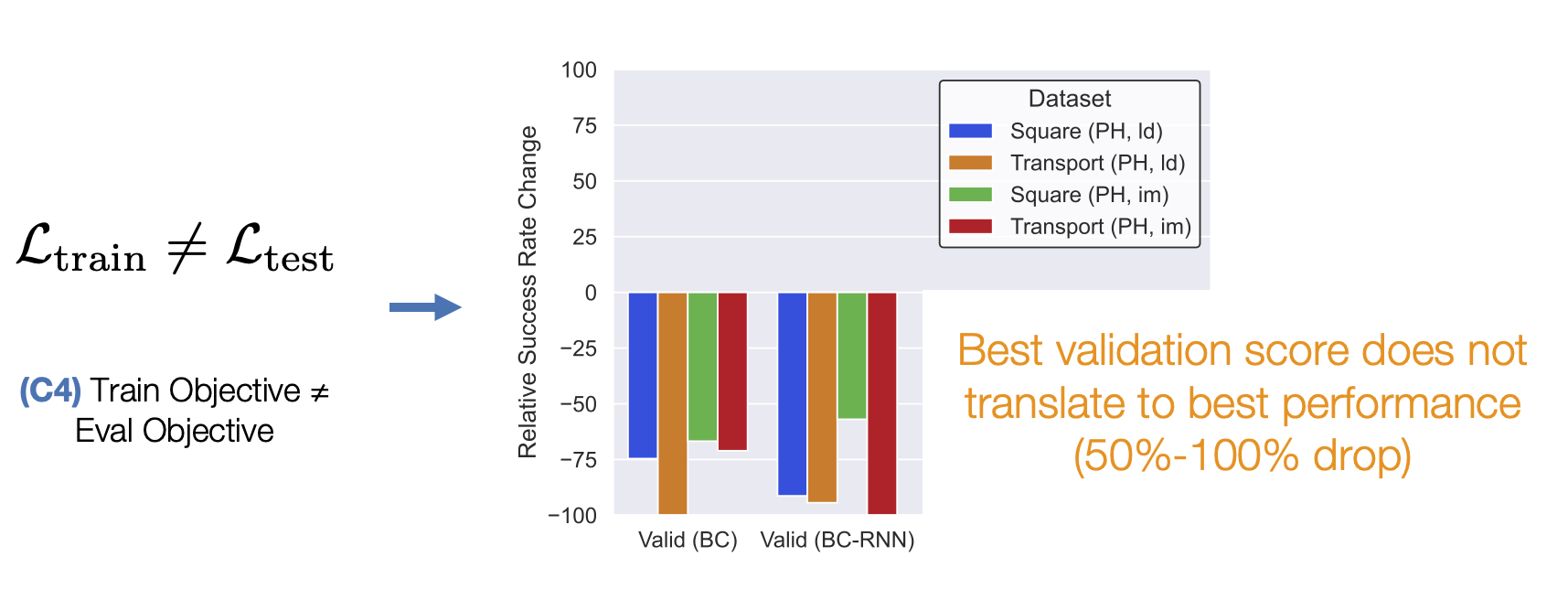
- (C4) Train Objective ≠ Eval Objective. Unlike traditional supervised learning, where validation loss is a strong indicator of how good a model is, policies are usually trained with surrogate losses. Consider an example where we train a policy via Behavioral Cloning from a set of demonstrations on a block lifting task. Here, the policy is trained to replicate the actions taken by the demonstrator, but this is not necessarily equivalent to optimizing the block lifting success rate (see the Dagger paper for a more precise explanation). This makes it hard to know which trained policy checkpoints are good without trying out each and every model directly on the robot – a time consuming process.
- (C5) Sensitivity to Agent Design Decisions. Performance can be very sensitive to important agent design decisions, like the observation space and hyperparameters used for learning.
Study Design
In this section, we summarize the tasks (5 simulated and 3 real), datasets (3 different variants), algorithms (6 offline methods, including 3 imitation and 3 batch reinforcement), and observation spaces (2 main variants) that we explored in our study.
Tasks
Task Reset Distributions
When measuring the task success rate of a policy, the policy is evaluated across several trials. At the start of each trial, the initial placement of all objects in the task are randomized from a task reset distribution. The videos below show this distribution for each task. This gives an impression of the range of different scenarios that a trained policy is supposed to be able to handle.







Datasets
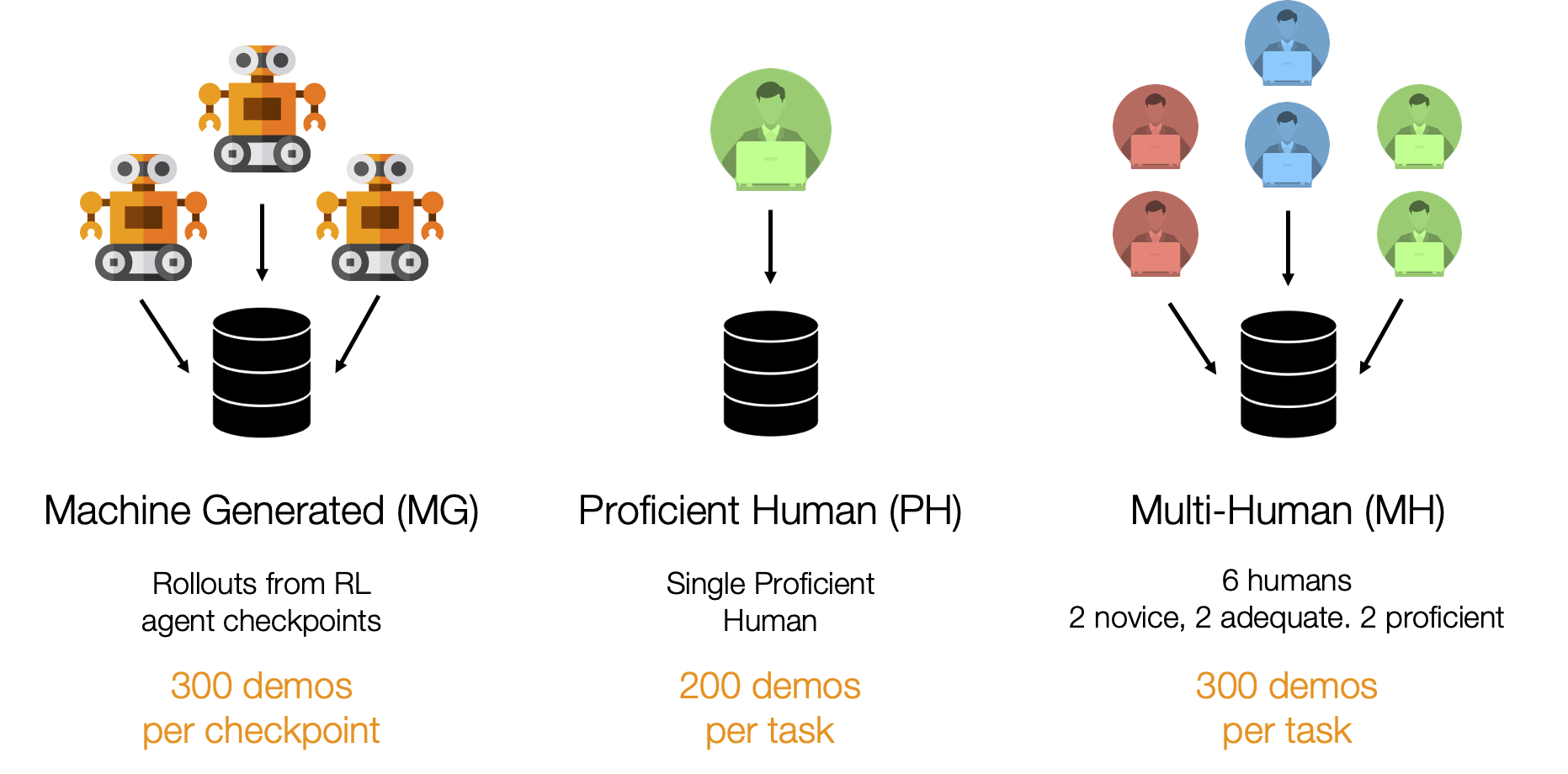
Machine-Generated
These datasets consist of rollouts from a series of SAC agent checkpoints trained on Lift and Can, instead of humans. As a result, they contain random, suboptimal, and expert data due to the varied success rates of the agents that generated the data. This kind of mixed quality data is common in offline RL works (e.g. D4RL, RLUnplugged).
Proficient-Human
These datasets consist of 200 demonstrations collected from a single proficient human operator using RoboTurk.
Multi-Human
These datasets consist of 300 demonstrations collected from six human operators of varied proficiency using RoboTurk. Each operator falls into one of 3 groups - “Worse”, “Okay”, and “Better” – each group contains two operators. Each operator collected 50 demonstrations per task. As a result, these datasets contain mixed quality human demonstration data. We show videos for a single operator from each group.
Algorithms
We evaluated 6 different offline learning algorithms in this study, including 3 imitation learning and 3 batch (offline) reinforcement learning algorithms.
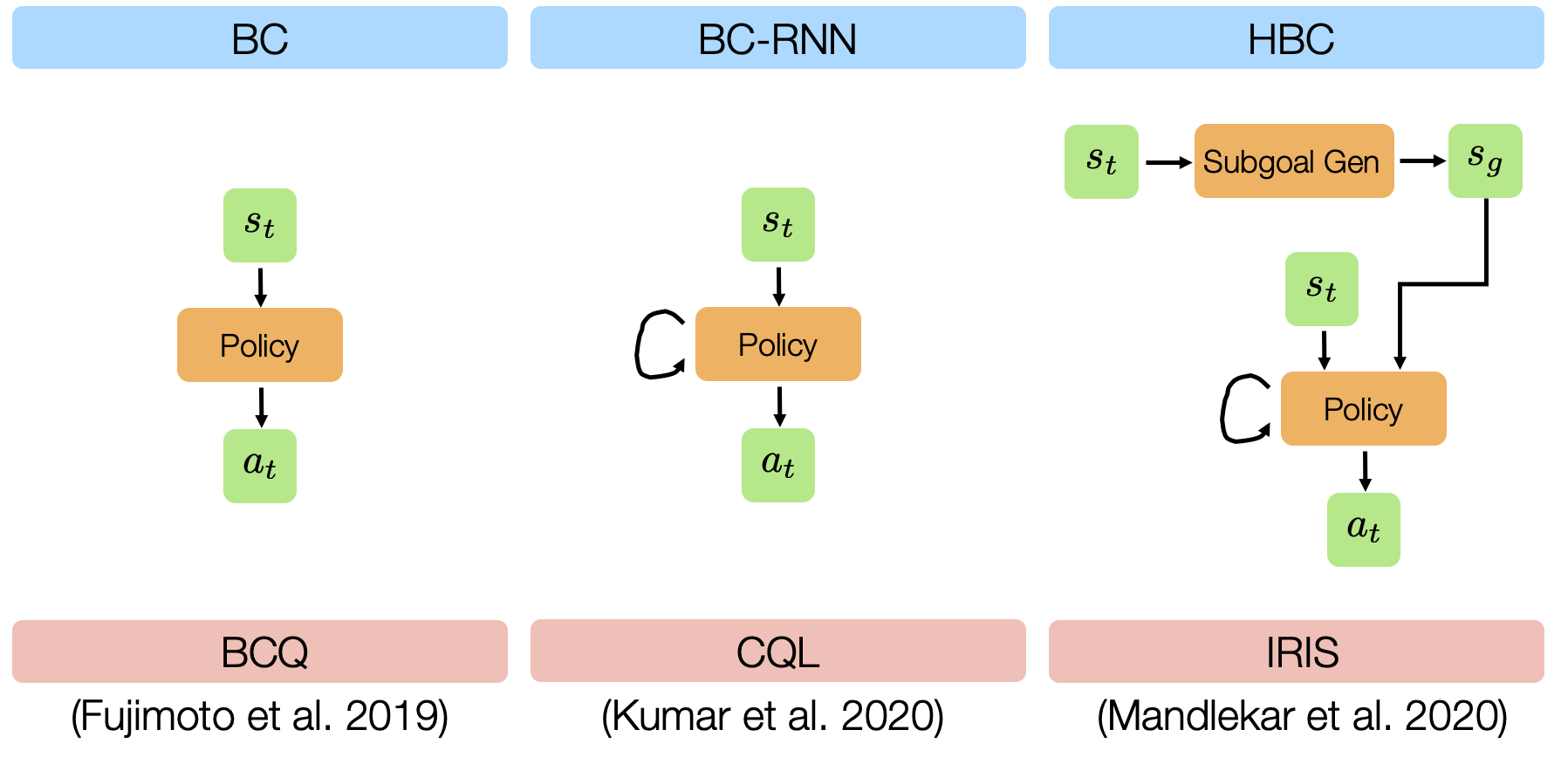
- BC: standard Behavioral Cloning, which is direct regression from observations to actions.
- BC-RNN: Behavioral Cloning with a policy network that’s a recurrent neural network (RNN), which allows modeling temporal correlations in decision-making.
- HBC: Hierarchical Behavioral Cloning, where a high-level subgoal planner is trained to predict future observations, and a low-level recurrent policy is conditioned on a future observation (subgoal) to predict action sequences (see Mandlekar*, Xu* et al. (2020) and Tung*, Wong* et al. (2021) for more details).
- BCQ: Batch-Constrained Q-Learning, a batch reinforcement learning method proposed in Fujimoto et al. (2019).
- CQL: Conservative Q-Learning, a batch reinforcement learning method proposed in Kumar et al. (2020).
- IRIS: Implicit Reinforcement without Interaction, a batch reinforcement learning method proposed in Mandlekar et al. (2020).
Observation Spaces
We study two different observation spaces in this work – low-dimensional observations and image observations.
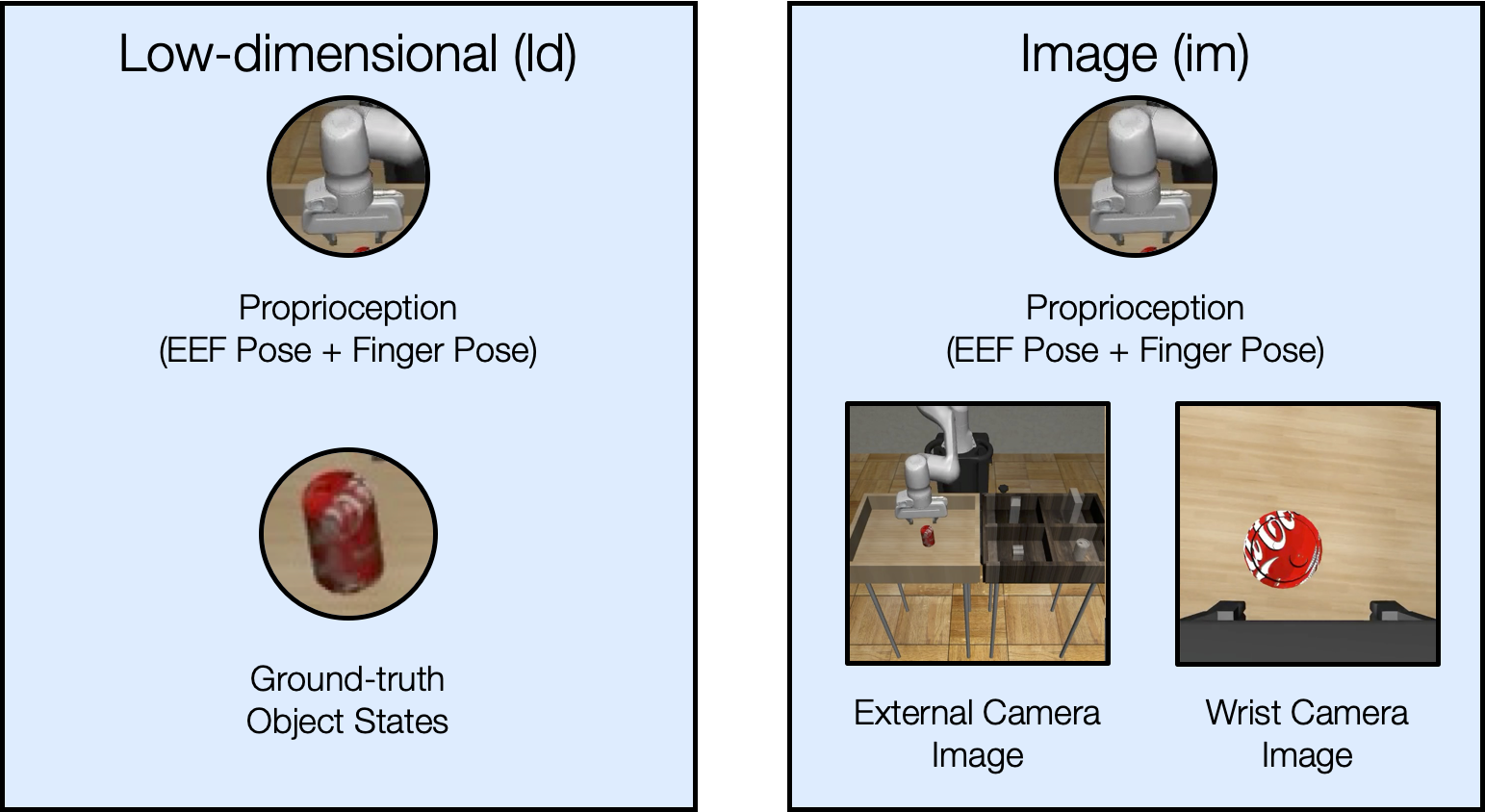
Image Observations
We provide examples of the image observations used in each task below.
Summary of Lessons Learned
In this section, we briefly highlight the lessons we learned from our study. See the paper for more thorough results and discussion.
Lesson 1: History-dependent models are extremely effective.
We found that there is a substantial performance gap between BC-RNN and BC, which highlights the benefits of history-dependence. This performance gap is larger for longer-horizon tasks (e.g. ~55% for the Transport (PH) dataset compared to ~5% for the Square (PH) dataset)) and also larger for multi-human data compared to single-human data (e.g.~25% for Square (MH) compared to ~5% for Square (PH)).
Lesson 2: Batch (Offline) RL struggles with suboptimal human data.
Recent batch (offline) RL algorithms such as BCQ and CQL have demonstrated excellent results in learning from suboptimal and multi-modal machine-generated datasets. Our results confirm the capacity of such algorithms to work well – BCQ in particular performs strongly on our agent-generated MG datasets that consist of a diverse mixture of good and poor policies (for example, BCQ achieves 91.3% success rate on Lift (MG) compared to BC which achieves 65.3%).
Surprisingly though, neither BCQ nor CQL performs particularly well on these human-generated datasets. For example, BCQ and CQL achieve 62.7% and 22.0% success respectively on the Can (MH) dataset, compared to BC-RNN which achieves 100% success. This puts the ability of such algorithms to learn from more natural dataset distributions into question (instead of those collected via RL exploration or pre-trained agents). There is an opportunity for future work in batch RL to resolve this gap.
Lesson 3: Improving offline policy selection is important.
Lesson 4: Observation space and hyperparameters play a large role in policy performance.

Lesson 5: Using human data for manipulation is promising.
Lesson 6: Study results transfer to real world.
We collected 200 demonstrations per task, and trained a BC-RNN policy using identical hyperparameters to simulation, with no hyperparameter tuning. We see that in most cases, performance and insights on what works in simulation transfer well to the real world.
Below, we present examples of policy failures on the Tool Hang task, which illustrate its difficulty, and the large room for improvement.
We also show that results from our observation space study hold true in the real world – visuomotor policies benefit strongly from wrist observations and pixel shift randomization.
Takeaways

- Learning from large multi-human datasets can be challenging.
- Large multi-human datasets hold promise for endowing robots with dexterous manipulation capabilities.
- Studying this setting in simulation can enable reproducible evaluation and insights can transfer to real world.
Please see the robomimic website for more information.
This blog post is based on the following paper:
- “What Matters in Learning from Offline Human Demonstrations for Robot Manipulation” by Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín.