![]()
The European Conference on Computer Vision (ECCV) 2020 is being hosted virtually from August 23rd - 28th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Contact and Human Dynamics from Monocular Video
 Authors: Davis Rempe, Leonidas J. Guibas, Aaron Hertzmann, Bryan Russell, Ruben Villegas, Jimei Yang
Authors: Davis Rempe, Leonidas J. Guibas, Aaron Hertzmann, Bryan Russell, Ruben Villegas, Jimei Yang
Contact: drempe@stanford.edu
Links: Paper | Video
Keywords: 3d human pose, 3d human motion, pose estimation, dynamics, physics-based, contact, trajectory optimization, character animation, deep learning
Curriculum DeepSDF
 Authors: Yueqi Duan, Haidong Zhu, He Wang, Li Yi, Ram Nevatia, Leonidas J. Guibas
Authors: Yueqi Duan, Haidong Zhu, He Wang, Li Yi, Ram Nevatia, Leonidas J. Guibas
Contact: duanyq19@stanford.edu
Links: Paper
Keywords: shape representation, implicit function, deepsdf, curriculum learning
Deformation-Aware 3D Model Embedding and Retrieval
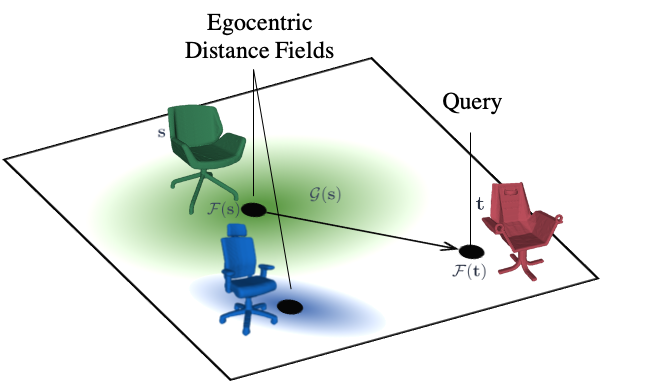 Authors: Mikaela Angelina Uy, Jingwei Huang, Minhyuk Sung, Tolga Birdal, Leonidas Guibas
Authors: Mikaela Angelina Uy, Jingwei Huang, Minhyuk Sung, Tolga Birdal, Leonidas Guibas
Contact: mikacuy@stanford.edu
Links: Paper | Video
Keywords: 3d model retrieval, deformation-aware embedding, non- metric embedding
Generative Sparse Detection Networks for 3D Single-shot Object Detection
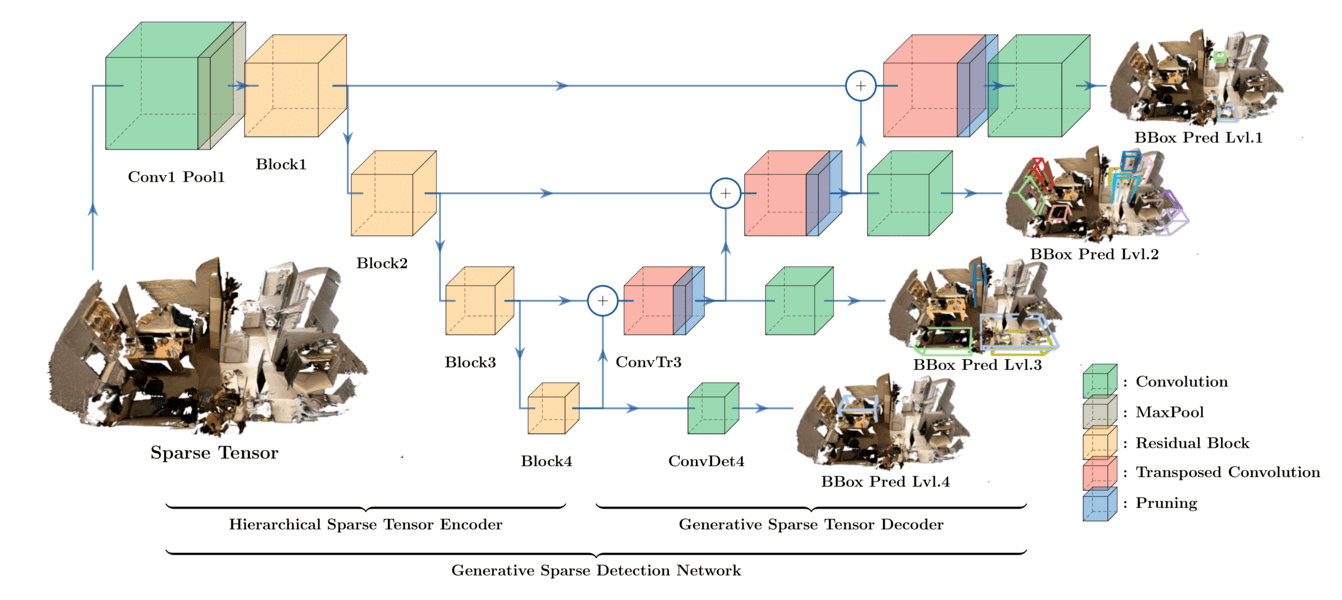 Authors: JunYoung Gwak, Christopher Choy, Silvio Savarese
Authors: JunYoung Gwak, Christopher Choy, Silvio Savarese
Contact: jgwak@cs.stanford.edu
Links: Paper | Video
Keywords: single shot detection, 3d object detection, generative sparsenetwork, point cloud
Learning 3D Part Assembly from A Single Image
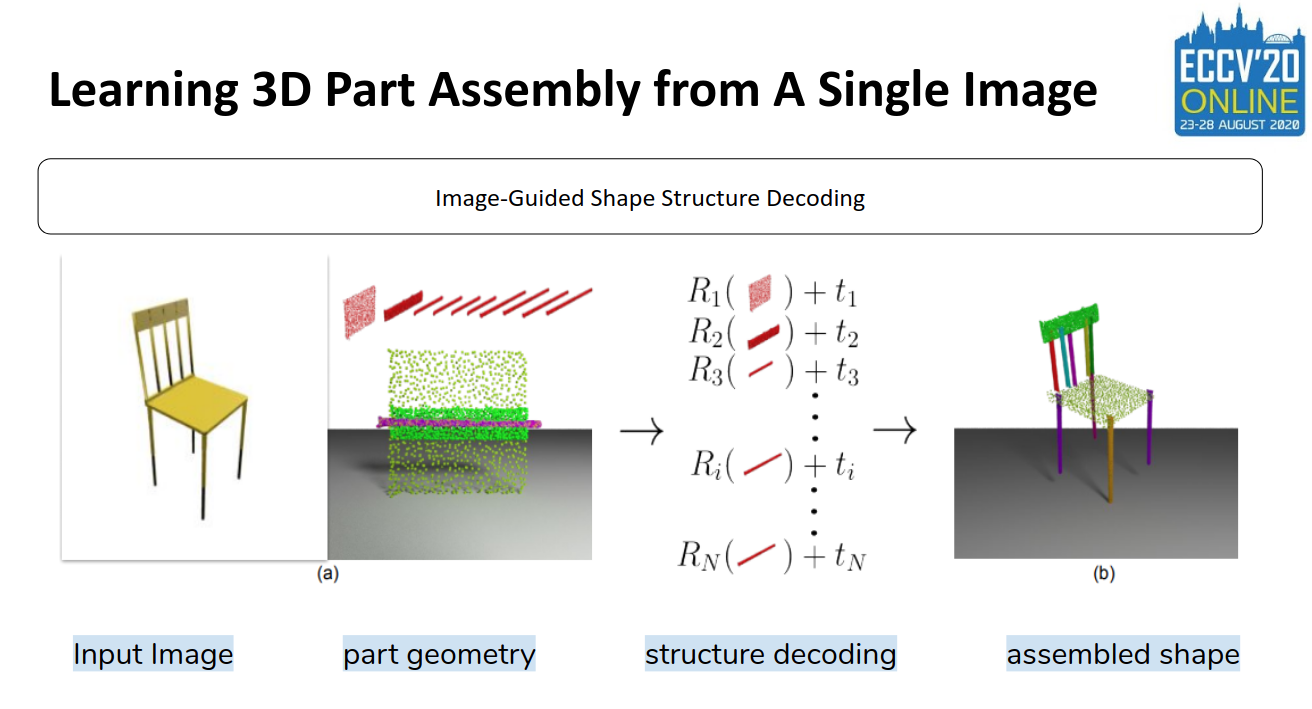 Authors: Yichen Li, Kaichun Mo, Lin Shao, Minhyuk Sung, Leonidas Guibas
Authors: Yichen Li, Kaichun Mo, Lin Shao, Minhyuk Sung, Leonidas Guibas
Contact: liyichen@cs.stanford.edu
Links: Paper | Video
Keywords: 3d vision, vision for robotics, 3d representation
Learning Predictive Models From Observation and Interaction
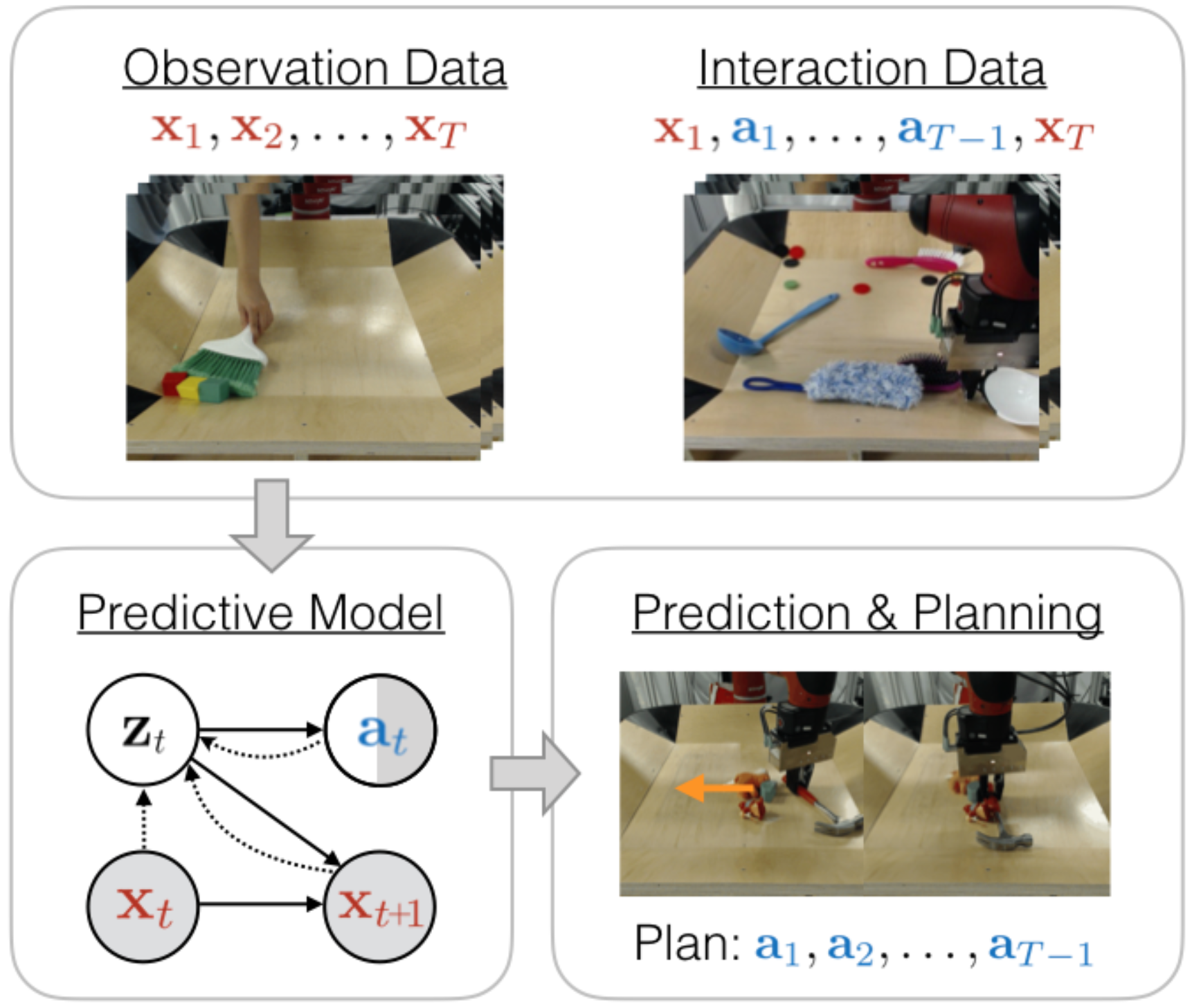 Authors: Karl Schmeckpeper, Annie Xie, Oleh Rybkin, Stephen Tian, Kostas Daniilidis, Sergey Levine, Chelsea Finn
Authors: Karl Schmeckpeper, Annie Xie, Oleh Rybkin, Stephen Tian, Kostas Daniilidis, Sergey Levine, Chelsea Finn
Contact: cbfinn@cs.stanford.edu
Links: Paper | Video
Keywords: video prediction, visual planning, action representations, robotic manipulation
PT2PC: Learning to Generate 3D Point Cloud Shapes from Part Tree Conditions
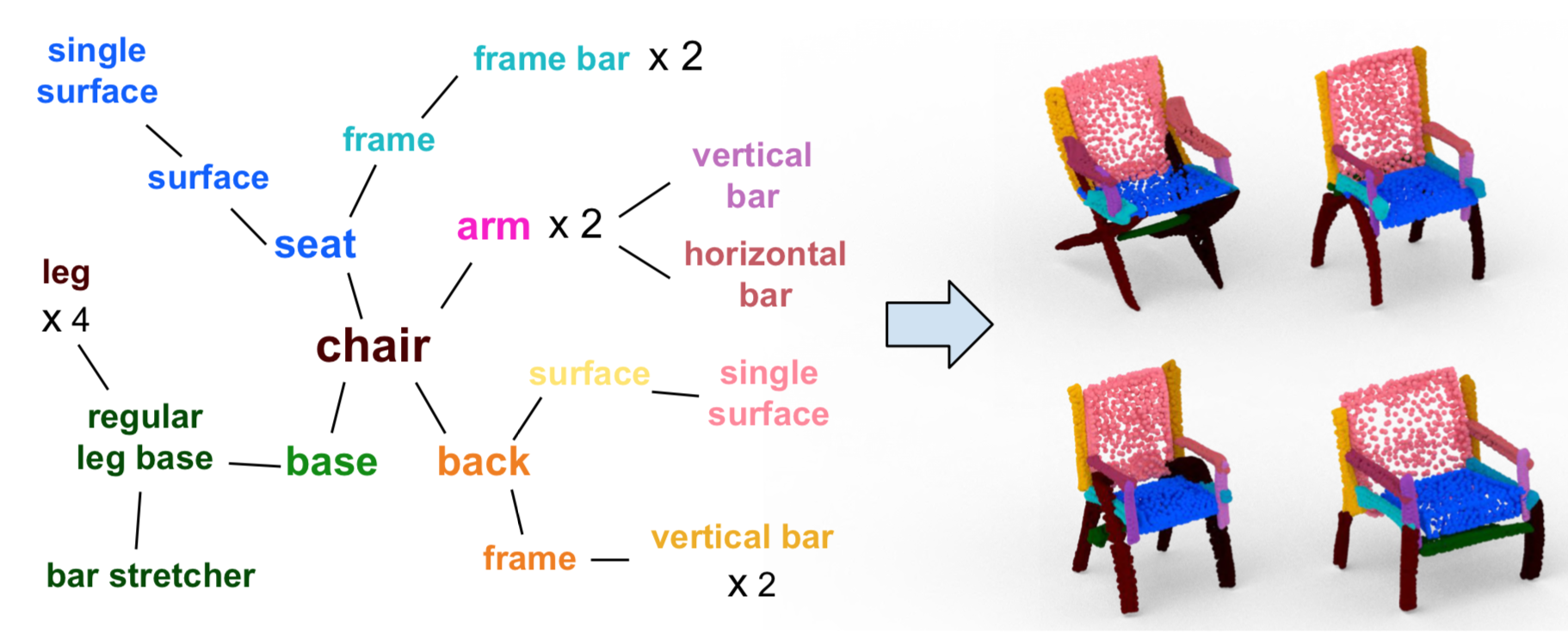 Authors: Kaichun Mo, He Wang, Xinchen Yan, Leonidas J. Guibas
Authors: Kaichun Mo, He Wang, Xinchen Yan, Leonidas J. Guibas
Contact: kaichunm@stanford.edu
Links: Paper | Video
Keywords: 3d vision and graphics, generative adversarial network, 3d point cloud
Pix2Surf: Learning Parametric 3D Surface Models of Objects from Images
 Authors: Jiahui Lei, Srinath Sridhar, Paul Guerrero, Minhyuk Sung, Niloy Mitra, Leonidas J. Guibas
Authors: Jiahui Lei, Srinath Sridhar, Paul Guerrero, Minhyuk Sung, Niloy Mitra, Leonidas J. Guibas
Contact: lei_jiahui@zju.edu.cn, ssrinath@cs.stanford.edu
Links: Paper | Video
Keywords: 3d reconstruction, multi-view, single-view, parametrization
Quaternion Equivariant Capsule Networks for 3D Point Clouds
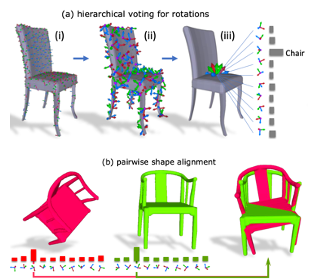 Authors: Yongheng Zhao, Tolga Birdal, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas, Federico Tombari
Authors: Yongheng Zhao, Tolga Birdal, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas, Federico Tombari
Contact: tbirdal@stanford.edu
Links: Paper
Keywords: equivariance, 3d point clouds, quaternion, weiszfeld algorithm, capsule networks, dynamic routing, riemannian
ReferIt3D: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes
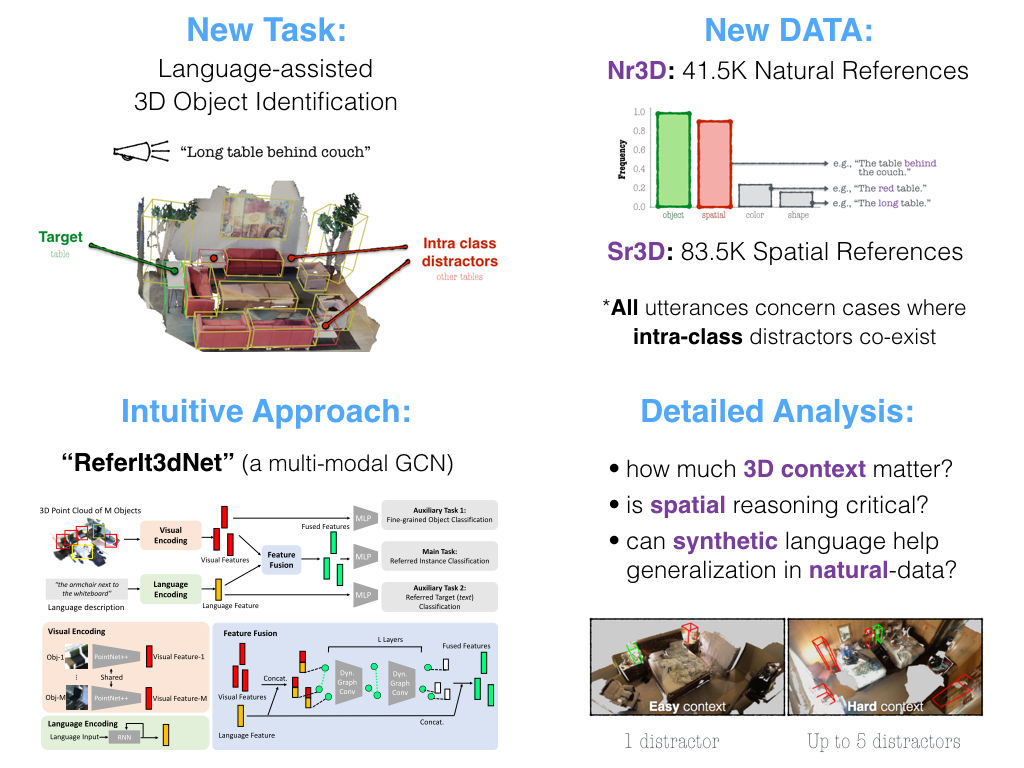 Authors: Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, Leonidas J. Guibas
Authors: Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, Leonidas J. Guibas
Contact: panos@cs.stanford.edu
Links: Paper | Video
Keywords: 3d neural-listeners, spatial relations, object identification, referential language
Robust and On-the-fly Dataset Denoising for Image Classification
 Authors: Jiaming Song, Yann Dauphin, Michael Auli, Tengyu Ma
Authors: Jiaming Song, Yann Dauphin, Michael Auli, Tengyu Ma
Contact: tsong@cs.stanford.edu
Links: Paper
Keywords: web supervision, noisy labels, robust data denoising
RubiksNet: Learnable 3D-Shift for Efficient Video Action Recognition
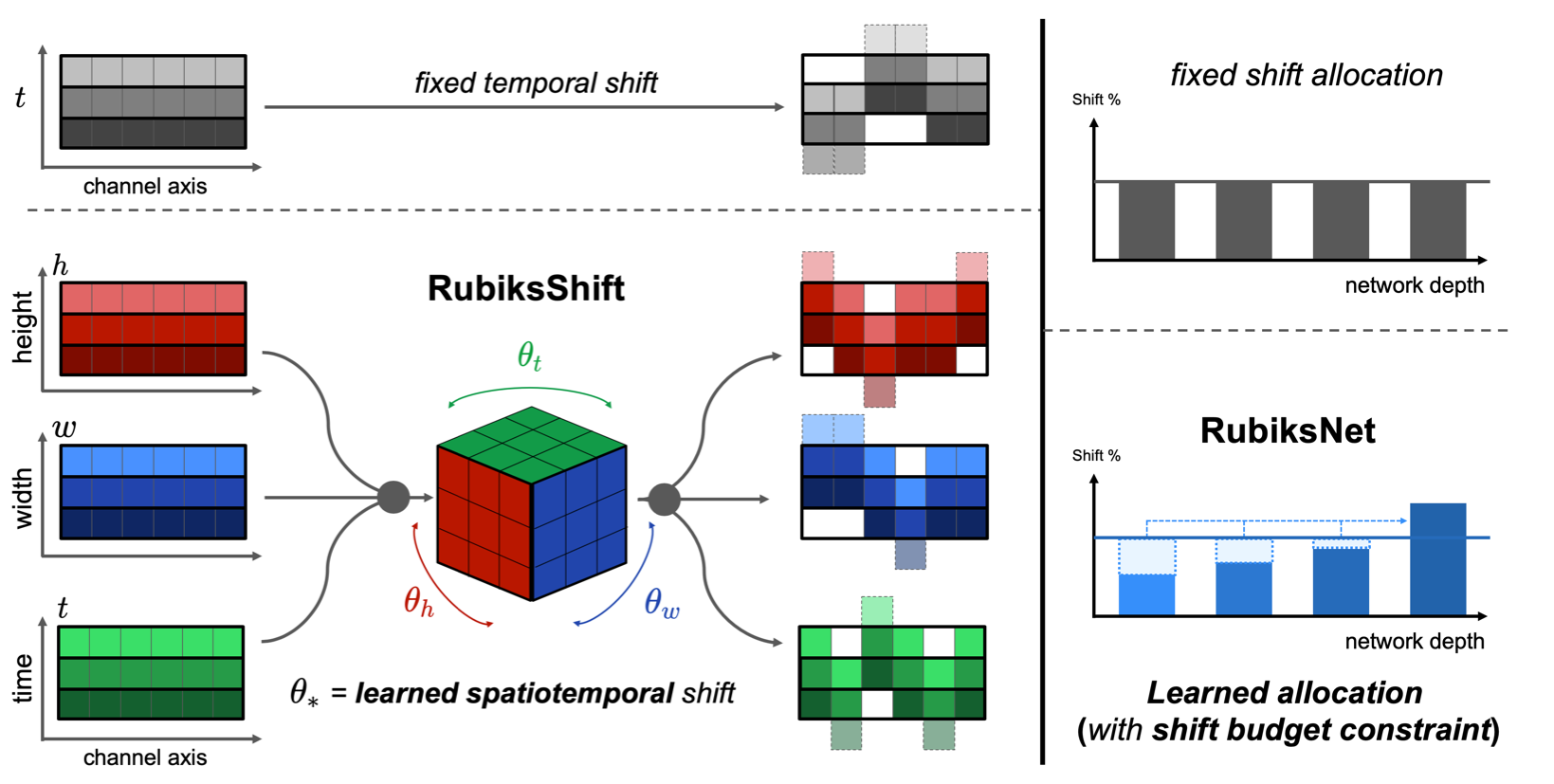 Authors: Linxi Fan*, Shyamal Buch*, Guanzhi Wang, Ryan Cao, Yuke Zhu, Juan Carlos Niebles, Li Fei-Fei
Authors: Linxi Fan*, Shyamal Buch*, Guanzhi Wang, Ryan Cao, Yuke Zhu, Juan Carlos Niebles, Li Fei-Fei
Contact: {jimfan,shyamal}@cs.stanford.edu
Links: Paper | Video | Website
Keywords: efficient action recognition, spatiotemporal, learnable shift, budget-constrained, video understanding
Trajectron++: Dynamically-Feasible Trajectory Forecasting With Heterogeneous Data
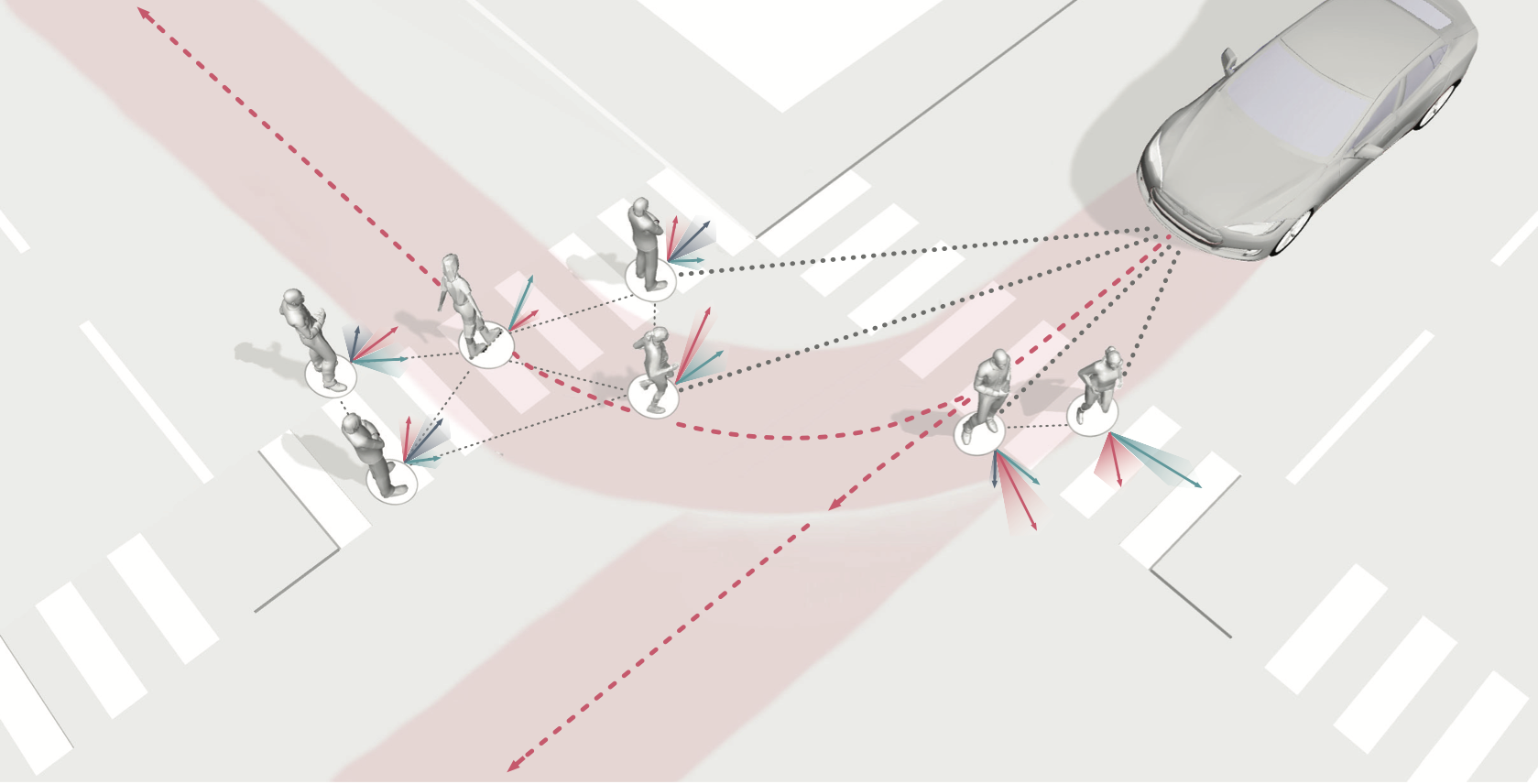 Authors: Tim Salzmann*, Boris Ivanovic*, Punarjay Chakravarty, Marco Pavone
Authors: Tim Salzmann*, Boris Ivanovic*, Punarjay Chakravarty, Marco Pavone
Contact: borisi@stanford.edu
Links: Paper | Blog Post
Keywords: trajectory forecasting, spatiotemporal graph modeling, human-robot interaction, autonomous driving
Trajectron++: Dynamically-Feasible Trajectory Forecasting With Heterogeneous Data
Authors: Tim Salzmann*, Boris Ivanovic*, Punarjay Chakravarty, Marco Pavone
Contact: borisi@stanford.edu
Links: Paper | Blog Post
Keywords: trajectory forecasting, spatiotemporal graph modeling, human-robot interaction, autonomous driving
Procedure Planning in Instructional Videos
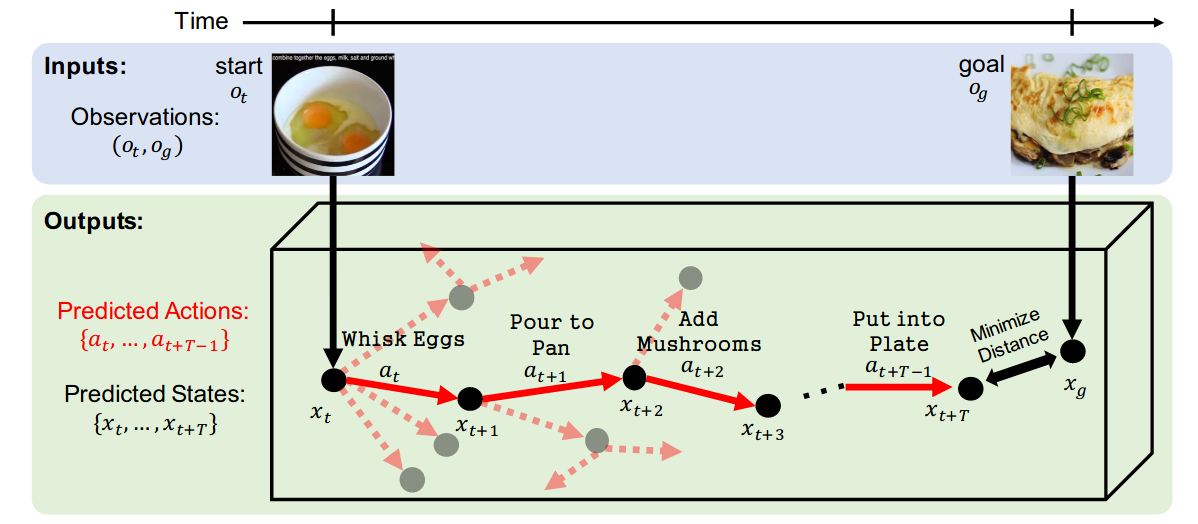 Authors: Chein-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, Juan Carlos Niebles
Authors: Chein-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, Juan Carlos Niebles
Contact: cy3@stanford.edu
Links: Paper | Website
Keywords: latent space planning, task planning, video understanding, representation for action and skill
We look forward to seeing you at ECCV 2020!