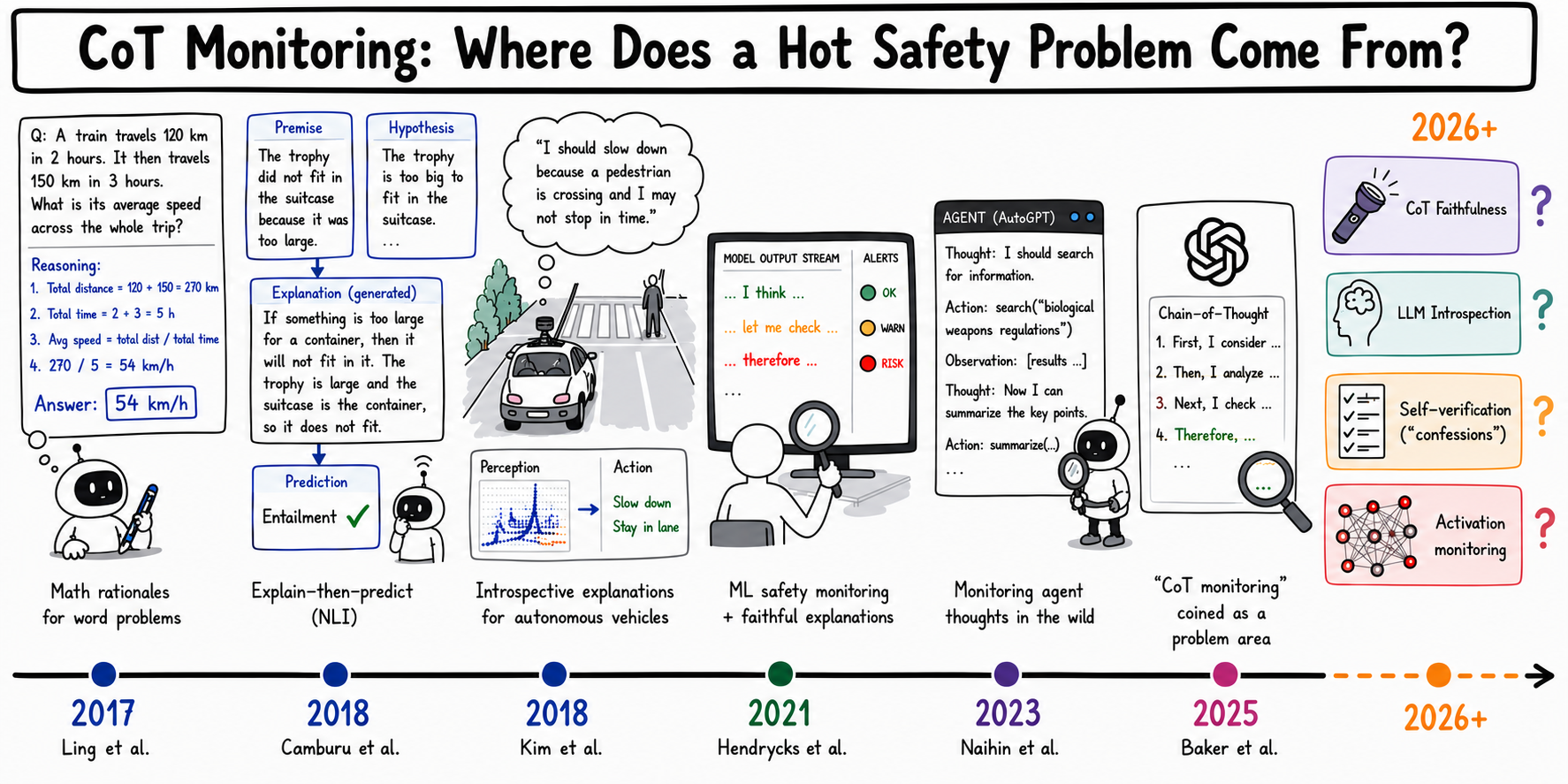
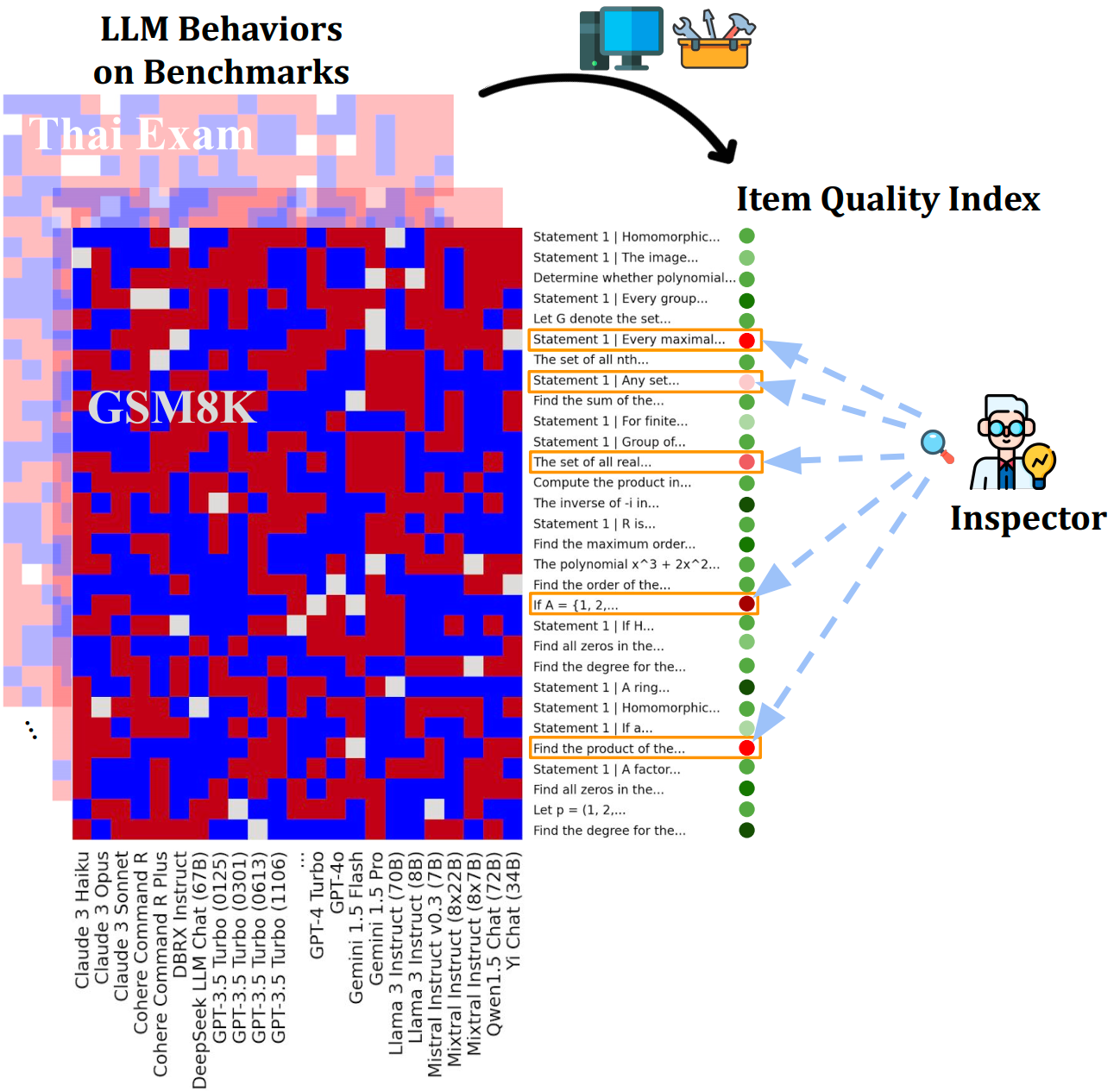
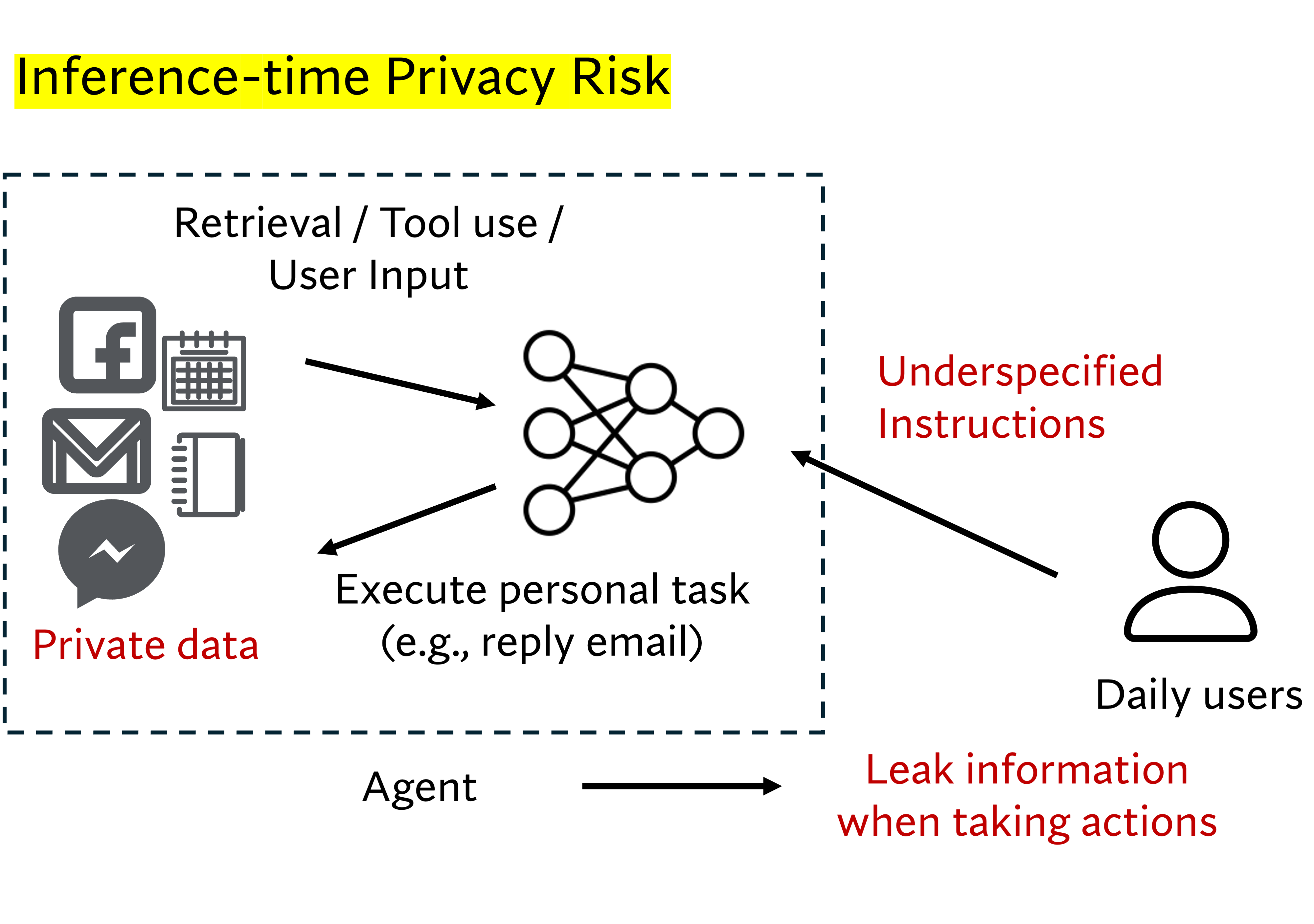
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
Pingyue Zhang*, Zihan Huang*, Yue Wang*, Jieyu Zhang*, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, Manling Li
We introduce Theory of Space, a benchmark testing whether foundation models can construct, revise, and exploit spatial beliefs through active exploration. Across six state-of-the-art models, we reveal a critical exploration bottleneck, a persistent text-vision modality gap, and severe belief iner...