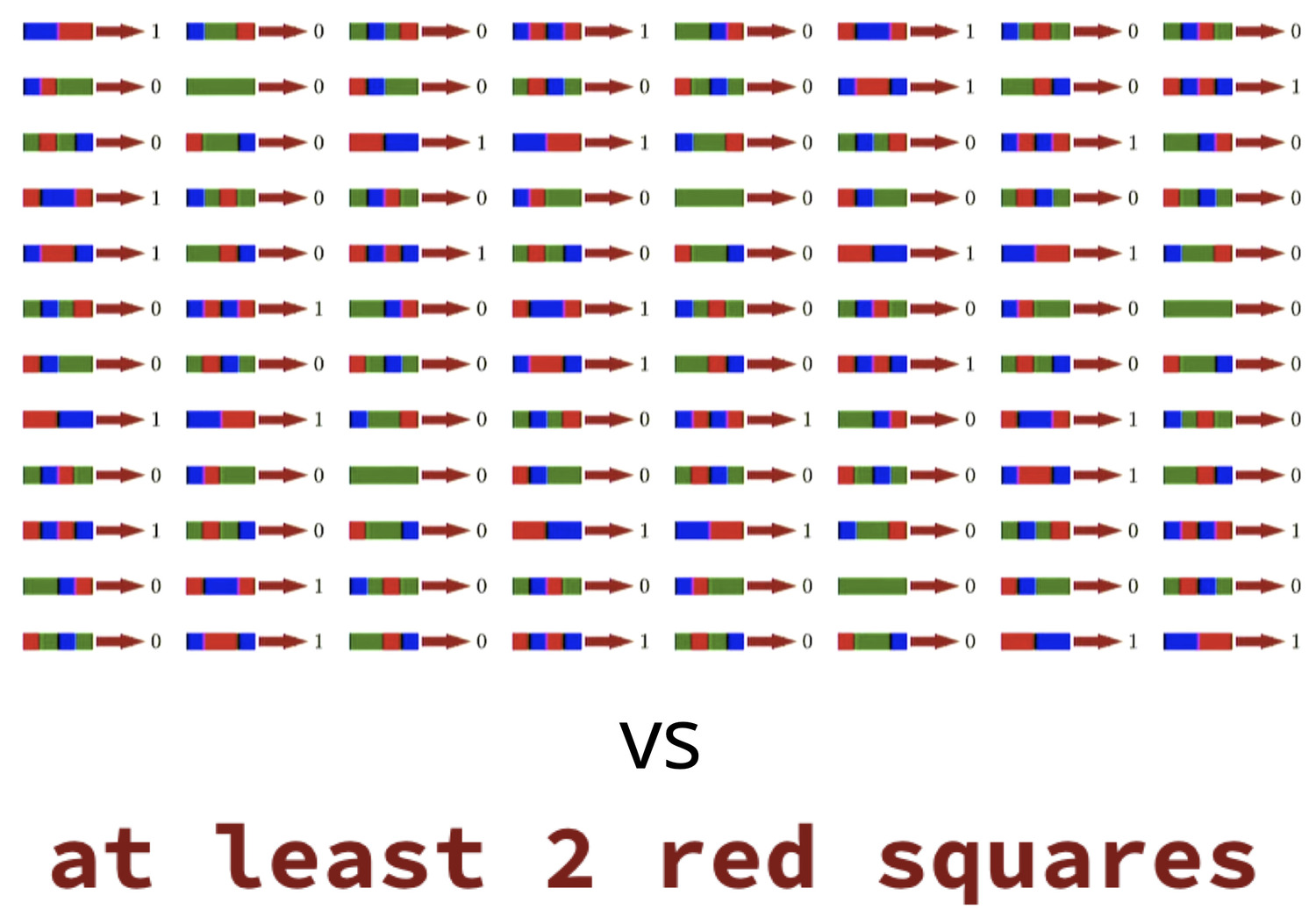
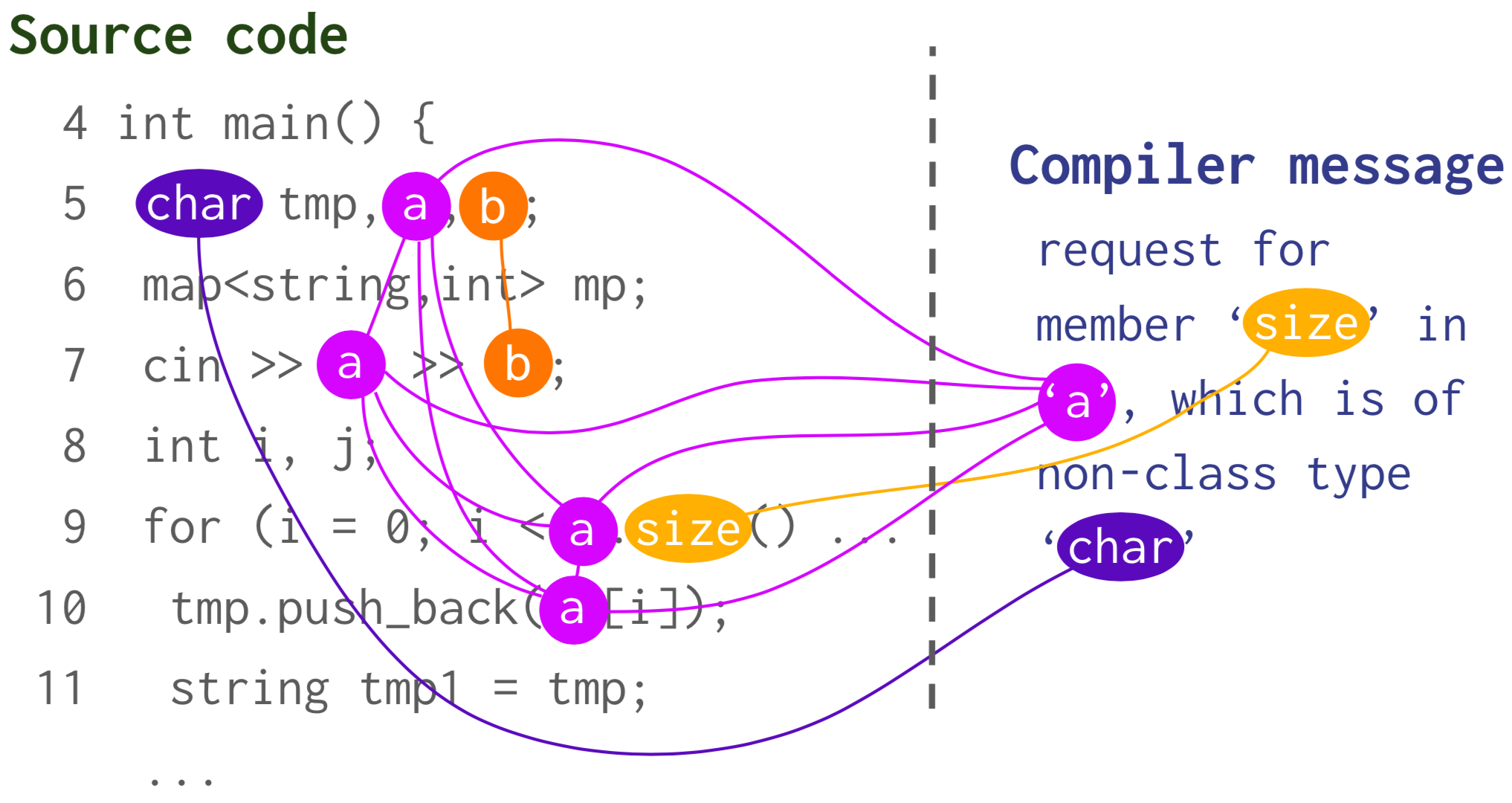
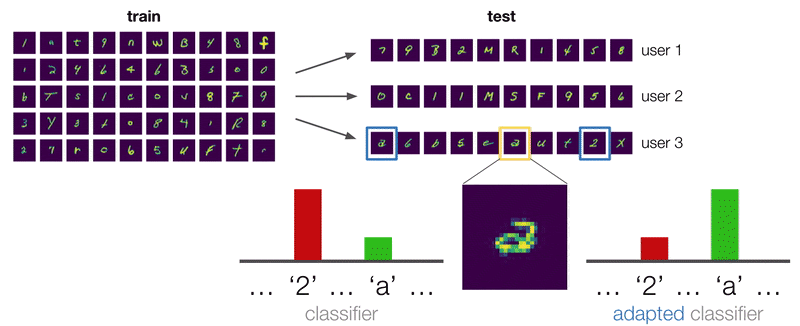
Identifying rare people, places, and things (entities) in text is a critical problem in AI, especially as the majority of entities are rare. We address this problem in our self-supervised system Bootleg. Bootleg learns to reason over entity types and relations for improved rare entity performance.