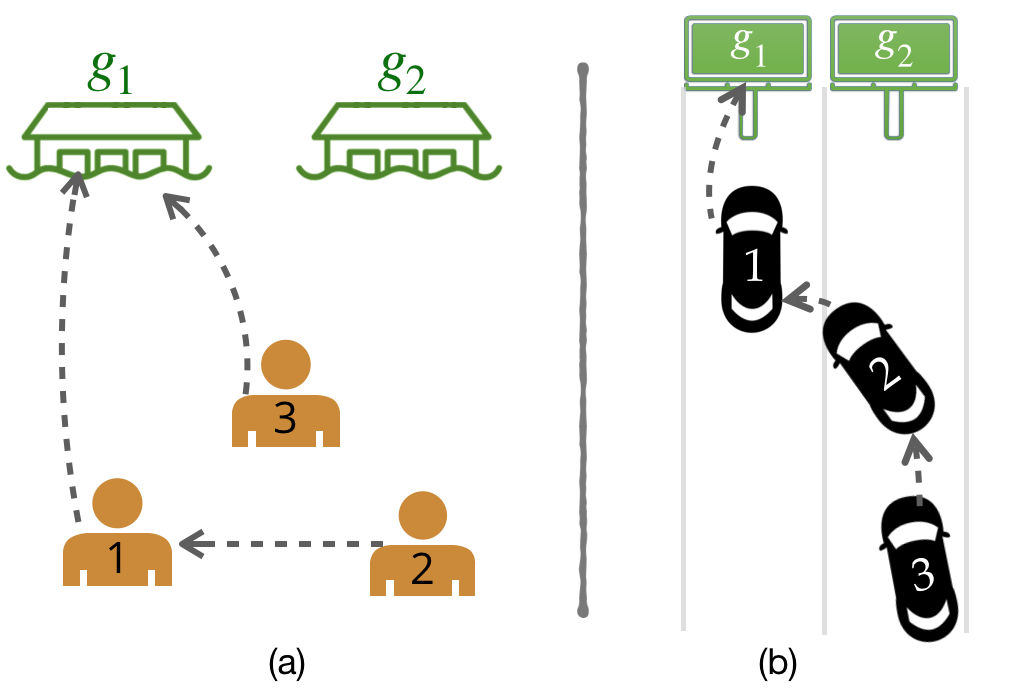
When learning from humans, we typically use data from only one form of human feedback. In this work, we investigate whether we can leverage data from multiple modes of feedback to learn more effectively from humans.
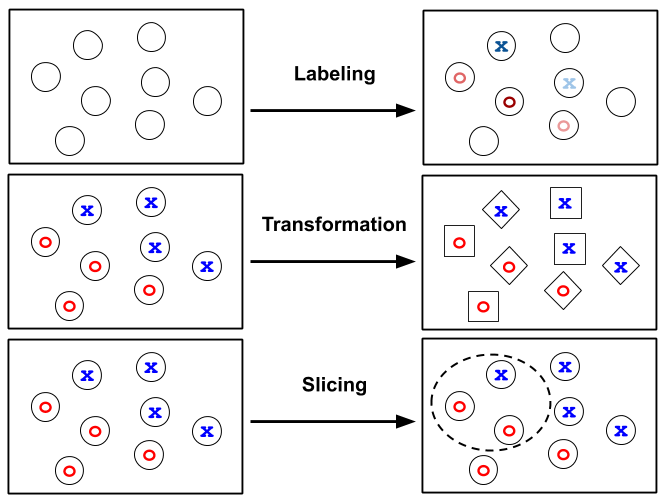
Machine learning practitioners are spending less time on model architectures and hardware optimizations and, instead, focusing on training data. We describe three powerful abstractions that practitioners can use to programmatically build and manage their training data.
On learning well-controlled fair representations of data, which make it much more difficult for any downstream machine learning models to discriminate.
Human–object interactions are multi-stepped and governed by physics as well human goals, customs, and biomechanics -- how can we teach machines to capture, understand, and replicate these interactions?
An overview of research at SAIL related to new techniques that allow us to look inside the black box of neural networks, to how it is possible to find and remove bias, and to how safety in autonomous systems can be assured.
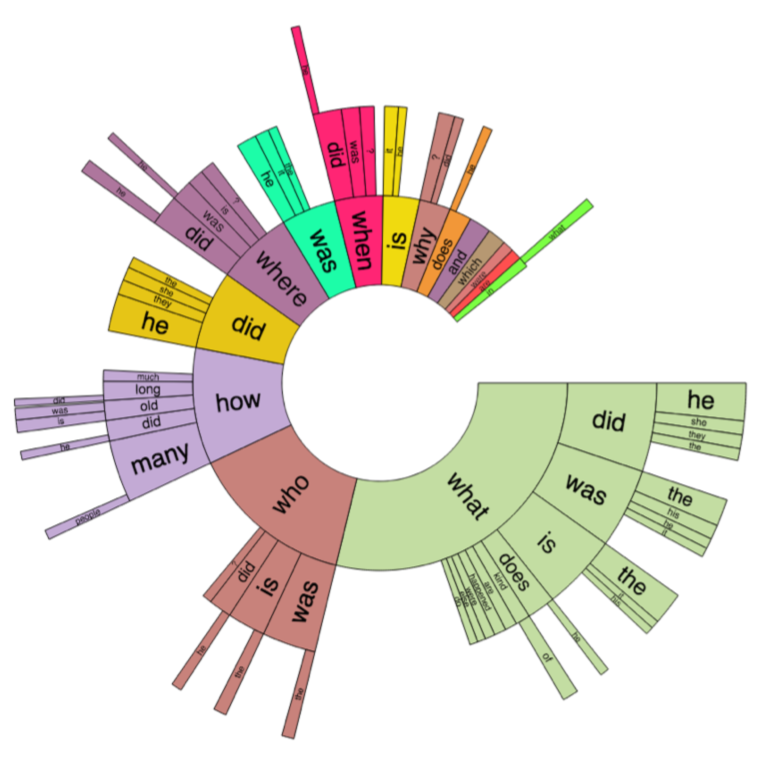
Summarizing work on two recent NLP datasets — CoQA and HotpotQA — and how they enable more conversational, explainable, and capable question answering systems.
What are the ethical responsibilities of AI researchers? Or to put it in more pragmatic terms, what are best practices AI researchers can follow to avoid unintended consequences of their research?