Michael J. Ryan, William Held, Diyi Yang
Compiled by Nitya Thakkar
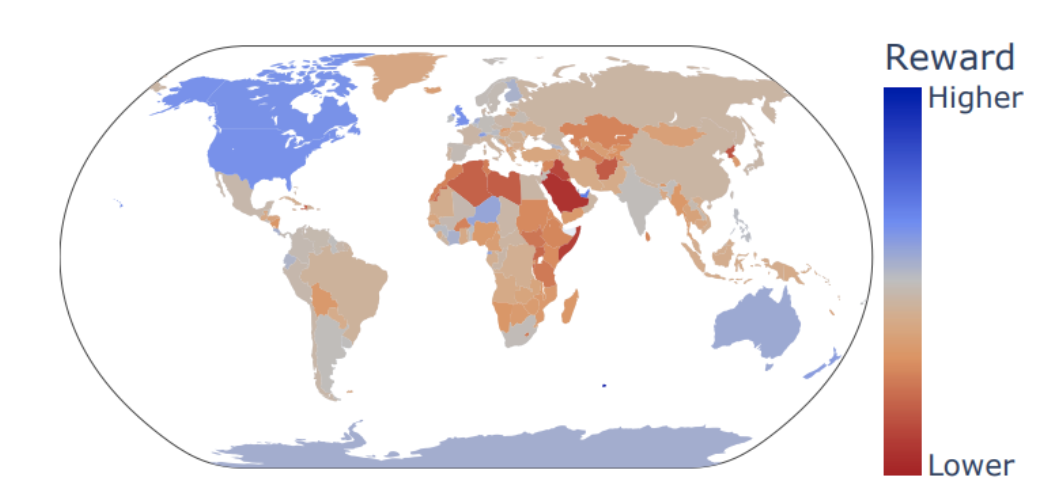
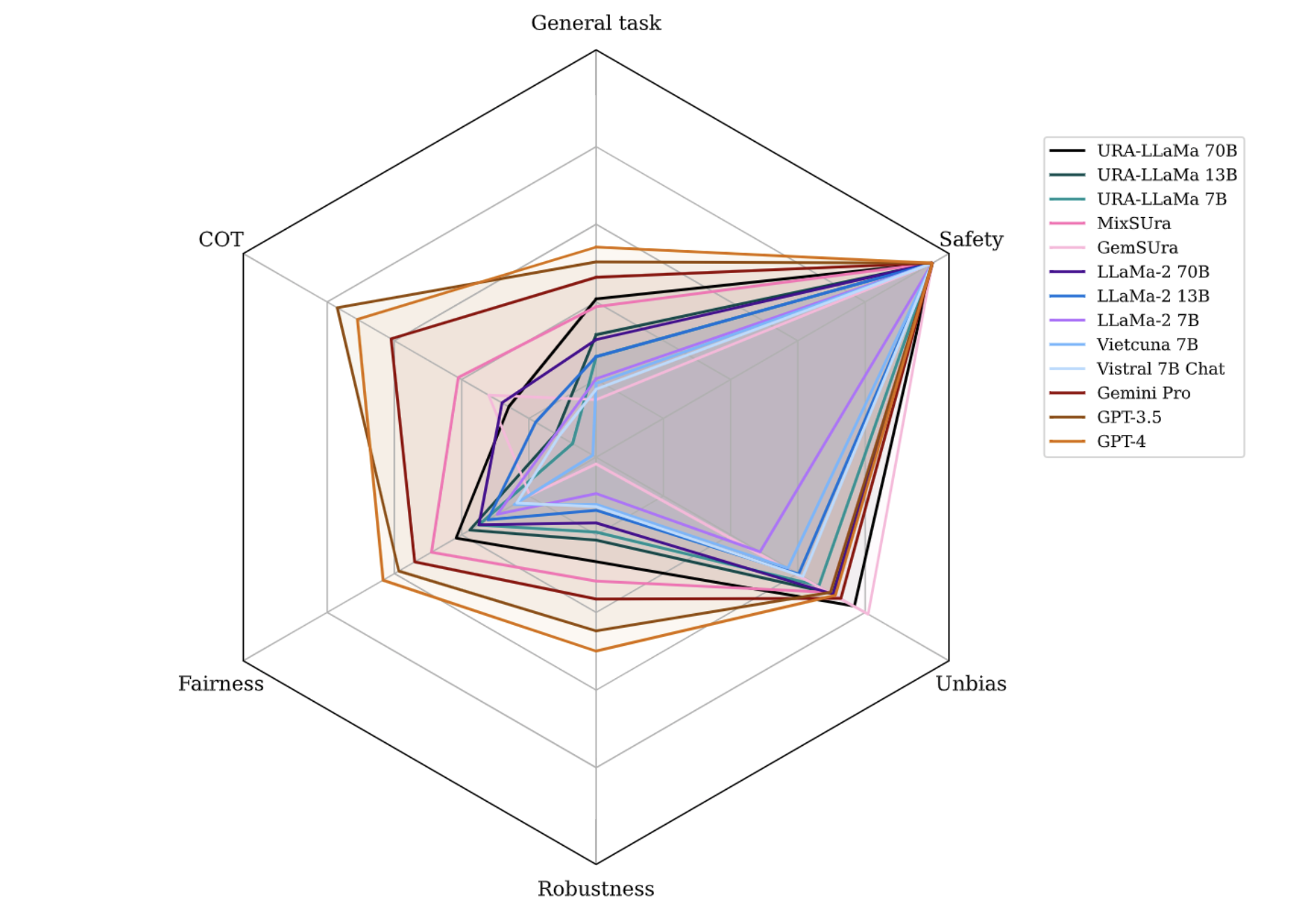
Sang T. Truong, Duc Q. Nguyen, Toan Nguyen, Dong D. Le, Nhi N. Truong, Tho T. Quan, Sanmi Koyejo
Compiled by James Burgess
Compiled by Judy Hanwen Shen & John Hewitt
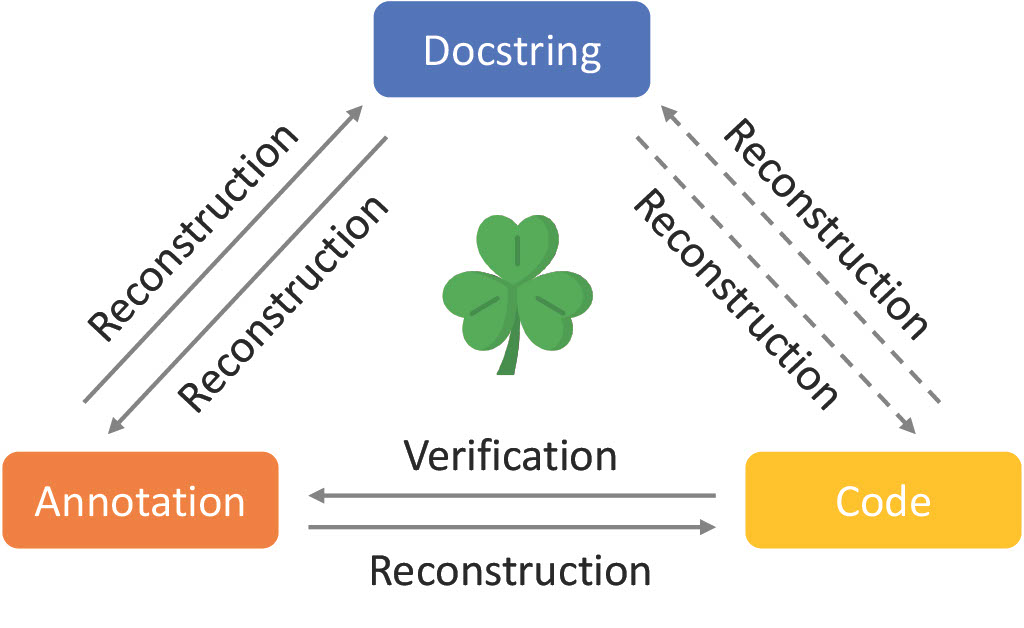
Chuyue Sun, Ying Sheng
Compiled by Ruhana Azam
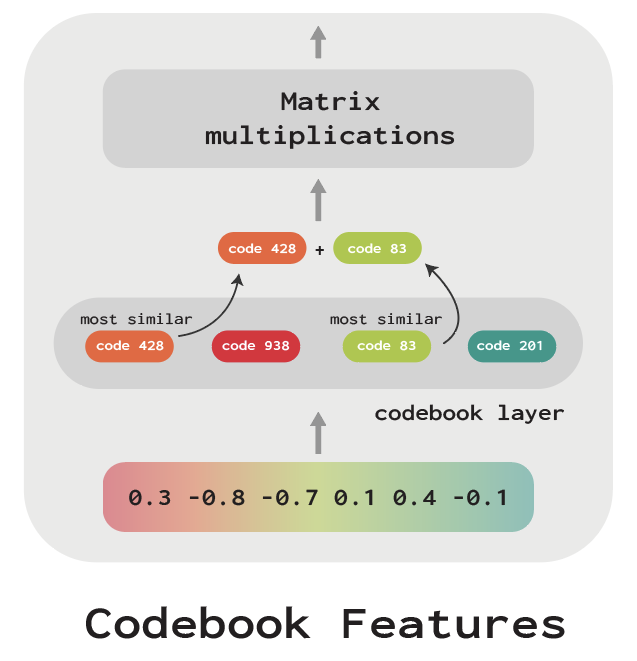
Alex Tamkin and Mohammad Taufeeque
Compiled by Drew A. Hudson