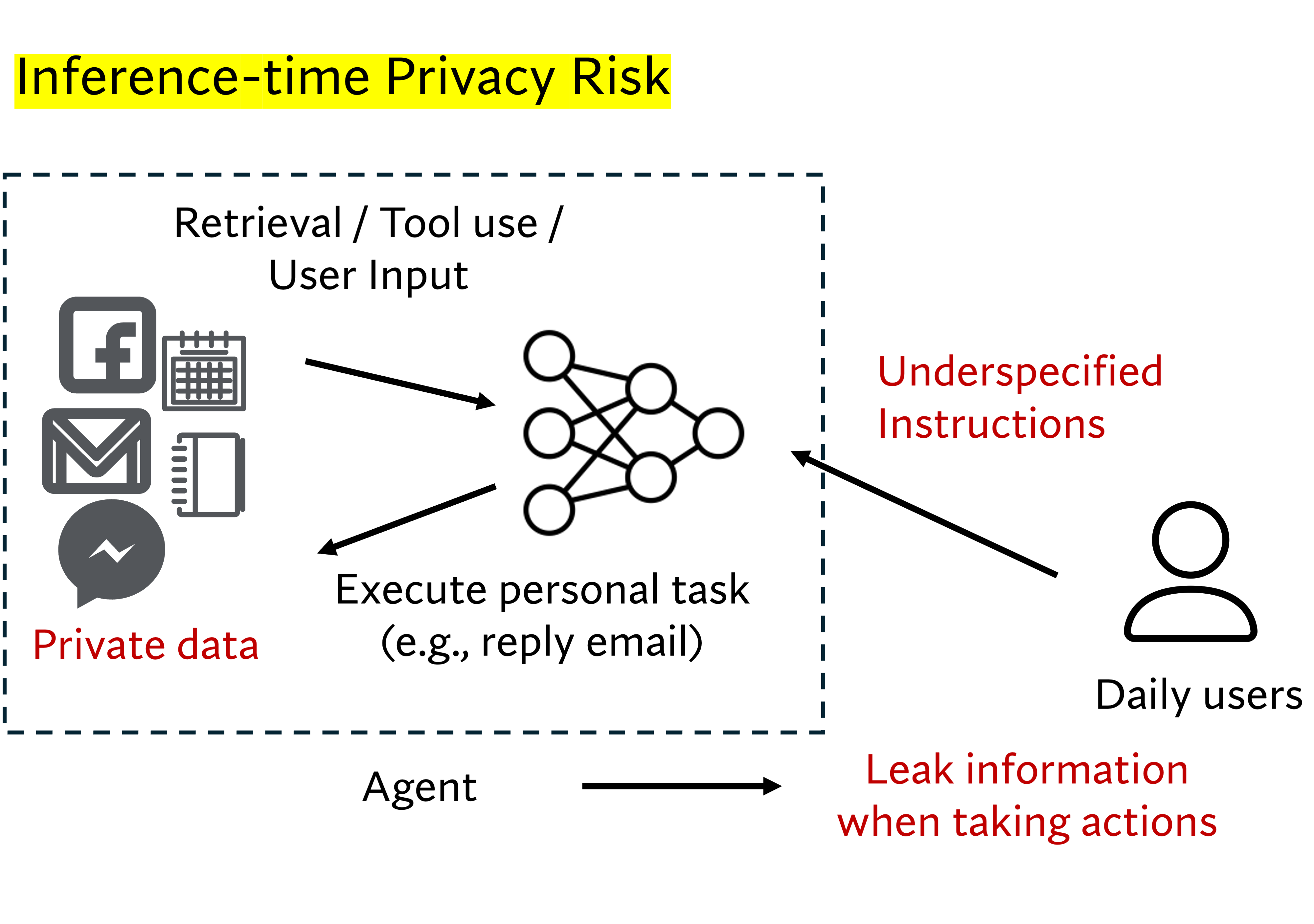
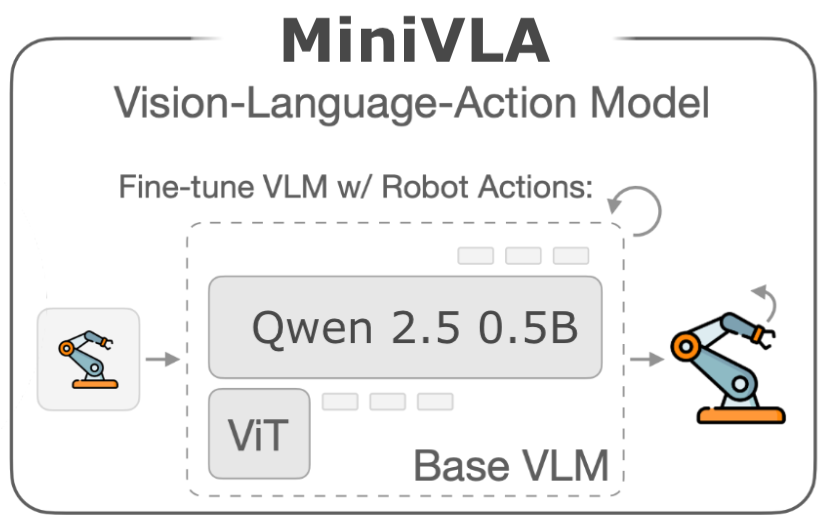
How do LLMs memorize long sequences of texts verbatim? In this work, we show that verbatim memorization is intertwined with the LM’s general capabilities.
We developed a new expert design and annotated clinical decision-making dataset that also allows for nuanced accuracy and fairness evaluations with expert preferences, uncertainty, and soft labels.