Publications
Cross-modal Attribute Transfer for Rescaling 3D Models
Lin Shao, Angel X. Chang, Hao Su, Manolis Savva, Leonidas Guibas
3DV 2017
Transfer geometrical and physical attributes from product catelog to 3D models in ShapeNet.
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Charles R. Qi, Li Yi, Hao Su, Leonidas J. Guibas
NIPS 2017
Deep network architecture for processing point cloud of cluttered scenes that often have non-uniform sampling density. Build upon PointNet, our CVPR2017 paper.
ComplementMe: Weakly-Supervised Component Suggestions for 3D Modeling
Minhyuk Sung, Hao Su, Vladimir G. Kim, Siddhartha Chaudhuri, and Leonidas Guibas
SIGGRAPH Asia 2017
Deep learning based approach for part-based 3D model synthesis. Given a partial construction (e.g., a chair in design), this method proposes a new component (e.g., arm) that is compatible with existing shape in style.
Learning Hierarchical Shape Segmentation and Labeling from Online Repositories
Li Yi, Leonidas J. Guibas, Aaron Hertzmann, Vladimir G. Kim, Hao Su, Ersin Yumer
SIGGRAPH 2017
Learn a consistent part hierarchy from a large collection of 3D models with scene-graph structure.
A Point Set Generation Network for 3D Object Reconstruction from a Single Image
Hao Su*, Haoqiang Fan*, Leonidas Guibas
CVPR 2017 (oral)
Build a generative neural network to directly output a set of unordered points. As applications, it can be used for single-image based 3D reconstruction and shape completion.
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Hao Su*, Charles Qi*, Kaichun Mo, Leonidas Guibas
CVPR 2017 (oral)
Build a neural network to directly consume an unordered point cloud as input, without converting to other 3D representations such as voxel grids first. Rich theoretical and empirical analyses are provided.
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation
Li Yi, Hao Su, Xingwen Guo, Leonidas Guibas
CVPR 2017 (spotlight)
A convolutional neural network on generic graphs of non-isometric structures. Spectral analysis (spectral domain synchronization) is conducted to enable effective kernel weight sharing. Part segmentation as an application.
Learning Shape Abstractions by Assembling Volumetric Primitives
Shubham Tulsiani, Hao Su, Leonidas Guibas, Alexei A. Efros, Jitendra Malik
CVPR 2017
Learn to abstract polygonal meshes by a flexible number of simple primitives such as cuboids. The abstraction is category consistent.
Learning Non-Lambertian Object Intrinsics across ShapeNet Categories
Jian Shi, Yue Dong, Hao Su, Stella X. Yu
CVPR 2017
Show that the material attributes of ShapeNet models can be useful to train algorithms for understanding the material and optical properties in Internet photos.
Beyond Holistic Object Recognition: Enriching Image Understanding with Part States
Cewu Lu, Hao Su, Yongyi Lu, Li Yi, Chikeung Tang, Leonidas Guibas
arxiv, 2016
Introduce the concept and computational model of "part state", an intermediate representation for object interaction modeling and image captioning. A dataset is provided, as well.
Volumetric and Multi-View CNNs for Object Classification on 3D Data
Hao Su*, Charles Qi*, Matthias Niessner, Angela Dai, Mengyuan Yan, Leonidas Guibas
CVPR 2016 (spotlight oral)
Novel architectures for 3DCNNs that take volumetric or multi-view representations as input.
Multilinear Hyperplane Hashing
Xianglong Liu, Xinjie Fan, Cheng Deng, Hao Su, Dacheng Tao
CVPR 2016
Efficient approximate point-to-plane search.
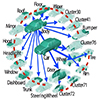
Synthesizing Training Images for Boosting Human 3D Pose Estimation
Wenzheng Chen, Huan Wang, Yangyan Li, Hao Su, Zhenhua Wang, Chenghe Tu, Dani Lischinski, Daniel Cohen-Or, Baoquan Chen
3DV 2016 (oral)
Extend RenderForCNN (my ICCV'15 paper) for 3D human pose estimation focusing on domain adaptation and data augmentation by automatic texture transfer.
ObjectNet3D: A Large Scale Database for 3D Object Recognition
Yu Xiang, Wonhui Kim, Wei Chen, Jingwei Ji, Christopher Choy, Hao Su, Roozbeh Mottaghi, Leonidas Guibas, Silvio Savarese
ECCV 2016 (spotlight oral)
A large-scale image-shape database by linking ImageNet and ShapeNet at instance level.
3D Attention-Driven Depth Acquisition for Object Identification
Kai Xu, Yifei Shi, Lintao Zheng, Junyu Zhang, Min Liu, Hui Huang, Hao Su, Daniel Cohen-Or, Baoquan Chen
Transactions on Graphics (SIGGRAPH ASIA 2016)
Teach robots to identify objects with fewest movements and scans. We trained a 3D attention model by reinforcement learning.
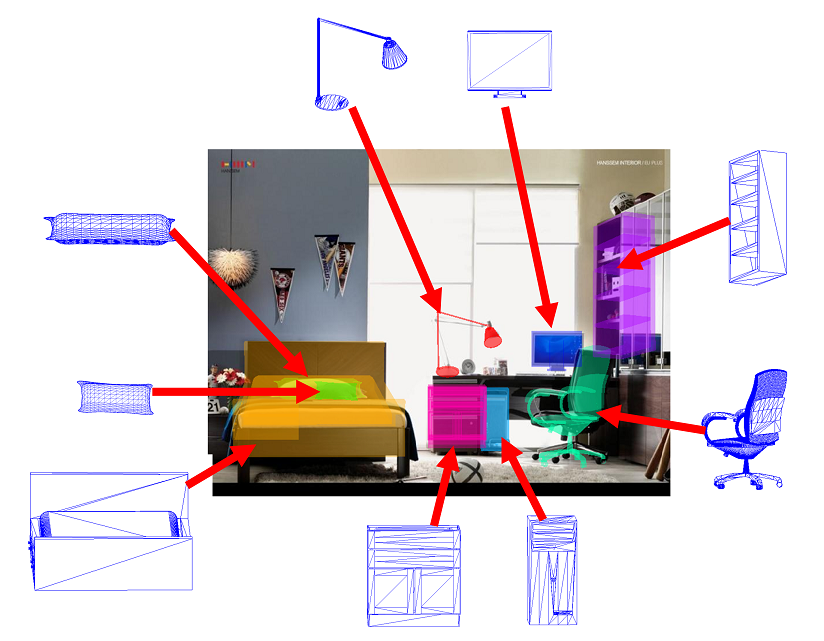
Unsupervised Texture Transfer from Images to Model Collections
Tuanfeng Y. Wang, Hao Su, Qixing Huang, Jingwei Huang, Leonidas J. Guibas, Niloy J. Mitra
Transactions on Graphics (SIGGRAPH ASIA 2016)
Transfer textures from product images to 3D shapes. The increased texture variation in ShapeNet is validated to be effective for RenderForCNN (my ICCV'15 paper).
A Scalable Active Framework for Region Annotation in 3D Shape Collections
Li Yi, Vladimir G. Kim, Duygu Ceylan, I-Chao Shen, Mengyuan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Sheffer, Leonidas Guibas
Transactions on Graphics (SIGGRAPH ASIA 2016)
Annotate the parts for ShapeNet by crowd-sourcing and label propagation with high efficiency and accuracy.
SHREC’16 Track: Large-Scale 3D Shape Retrieval from ShapeNet Core55
M. Savva, F. Yu, Hao Su, M. Aono, B. Chen, D. Cohen-Or, W. Deng, H. Su, S. Bai, X. Bai, N. Fish, J. Han, E. Kalogerakis, E. G. Learned-Miller, Y. Li, M. Liao, S. Maji, A. Tatsuma, Y. Wang, N. Zhang, Z. Zhou
EuroGraphics SHREC2016 Workshop Report
Technical report for SHREC'16, the most renowned challenge for 3D shape retrieval.
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva*, Shuran Song, Hao Su*, Jianxiong Xiao, Li Yi, Fisher Yu
Corresponding author, student co-lead, arxiv, 2016
The official report of ShapeNet, an object-centric database of semantics, geometry and physics.
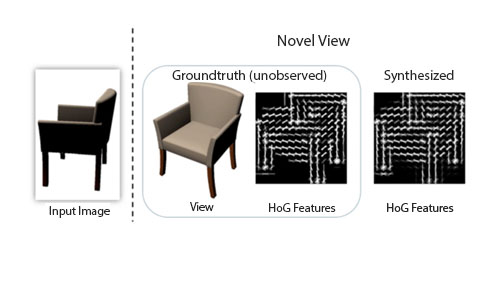
3D-Assisted Image Feature Synthesis for Novel Views of an Object
Hao Su*, Fan Wang*, Li Yi, Leonidas Guibas
ICCV 2015 (oral, acceptance rate: 2%)
Synthesize features at novel views of a 3D object from the observed viewpoint, leveraging on the geometric priors from ShapeNet.
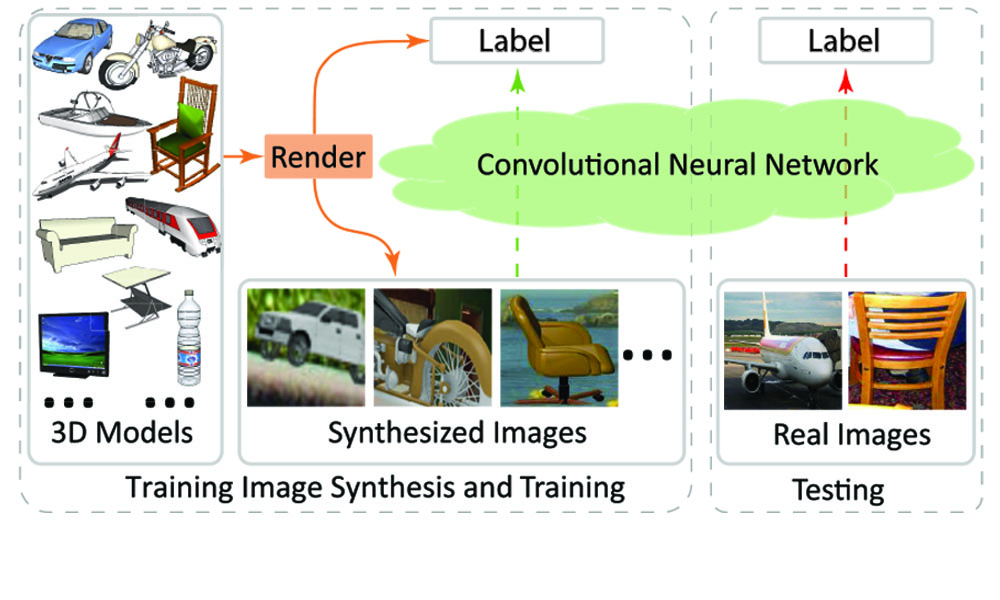
Render for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views
Hao Su*, Charles Qi*, Yangyan Li, Leonidas Guibas
ICCV 2015 (oral, acceptance rate: 2%)
Show that large-scale synthetic data rendered from virtual world may greatly benefit deep learning to work in real world. Deliver a state-of-the-art viewpoint estimator.
Joint Embeddings of Shapes and Images via CNN Image Purification
Hao Su*, Yangyan Li*, Charles Qi, Noa Fish, Daniel Cohen-Or, Leonidas Guibas
Transactions on Graphics (SIGGRAPH Asia 2015)
Cross-modality learning of 3D shapes and 2D images by neural networks. A joint embedding space that is sensitive to 3D geometry difference but agnostic to other nuisances is constructed.
ImageNet Large Scale Visual Recognition Challenge
Olga Russakovsky*, Jia Deng*, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, Li Fei-Fei
IJCV 2015
The technical report for ImageNet Challenge.
Estimating Image Depth using Shape Collections
Hao Su, Qixing Huang, Niloy Mitra, Yangyan Li, Leonidas Guibas
Transactions on Graphics (SIGGRAPH 2014)
Learn to estimate the depth from a single input image assisted by geometric priors from a 3D shape collection (later merged to ShapeNet).
Fine-Grained Semi-Supervised Labeling of Large Shape Collections
Qixing Huang, Hao Su, Leonidas Guibas
Transactions on Graphics (SIGGRAPH Asia 2013)
Fine-grained 3D shape classification.
Multi-level structured image coding on high-dimensional image representation
Li-Jia Li*, Jun Zhu*, Hao Su, Eric. P. Xing, Li Fei-Fei
ACCV 2013
Multi-layer sparse coding for compressing ObjectBank representation.
Crowd-sourcing Annotations for Visual Object Detection
Hao Su, Jia Deng, Li Fei-Fei
AAAI 2012 Human Computation Workshop
A system to annotate object bounding boxes for ImageNet by crowd-sourcing. This system is used to collect bounding boxes for ImageNet Large Scale Visual Recognition Challenges.
Object Bank: A High-Level Image Representation for Scene Classification & Semantic Feature Sparsification
Hao Su*, Li-Jia Li*, Eric.P. Xing, Li Fei-Fei
NIPS 2010 (top 10 most cited paper in NIPS since 2010)
Learn to describe scenes by responses from object detectors. Can be viewed as a layer-wise trained CNN (Gradient-HoG-Part-Object-Scene hierarchy).
Learning a dense multi-view representation for detection, viewpoint classification and synthesis of object categories
Hao Su*, Min Sun*, Li Fei-Fei, Silvio Savarese
ICCV 2009 (oral, acceptance rate: 4%)
Continuous viewpoint estimation by a graphical model.
A Multi-View Probabilistic Model for 3D Object Classes
Hao Su*, Min Sun*, Li Fei-Fei, Silvio Savarese
CVPR 2009
Discrete viewpoint estimation by a graphical model.
Construction and Analysis of a Large Scale Image Ontology
Jia Deng, Hao Su, Minh Do, Kai Li, Li Fei-Fei
VSS 2009
ImageNet analysis paper.
FPNN: Field Probing Neural Networks for 3D Data
Yangyan Li, Soeren Pirk, Hao Su, Charles R. Qi, Leonidas J. Guibas
NIPS 2016
A very efficient 3D deep learning method for volumetric data processing that takes advantage of data sparsity in 3D fields.
Density Estimation via Discrepancy
Kun Yang, Hao Su, Wing Wong
arXiv:1509.06831, 2015
Estimating the density of a population by adaptively partitioning the space according to discrepancy criteria.
co-BPM: a Bayesian Model for Estimating Divergence and Distance of Distributions
Kun Yang, Hao Su, Wing Wong
Journal of Computational and Graphical Statistics
Measuring discrepancy of two samples by a Bayesian approach.
Reverse Top-k Search using Random Walk with Restart
Adams Wei Yu, Nikos Mamoulis, Hao Su
VLDB 2014
Given a node in a large-scale transition graph, how to efficiently find those nodes that have this given node as a top k nearest neighbour (reverse top-k search problem). The inverse of PageRank problem.
Efficient Euclidean Projections onto the Intersection of Norm Balls
Hao Su*, Adams W. Yu*, Li Fei-Fei
ICML 2012
Sparse-group LASSO model is a linear regression model that encourages simultaneous element-wise sparsity and group-wise sparsity. This work studies the key component in optimizing such a model by projection-based algorithms.
Pathlet Learning for Compressing and Planning Trajectories
Chen Chen, Hao Su, Qixing Huang, Lin Zhang, Leonidas Guibas
SIGSPATIAL 2013
Discover common sub-structures from a large set of taxi trajectories. Formulated as a linear programming problem, in a spirit similar to probabilistic topic models (pLSA).